Similarity search
任務
實現近似串查詢,近似串有兩種度量方式:Levenshtein edit
distance和Jaccard
index。需要實現SimSeacher類的createIndex、searchED、searchJaccard三個方法。
代碼中實現了brute-force、tournament sort、MergeSkip@LLL08和DivideSkip@LLL08四種查詢算法。
BruteForce
枚舉所有字符串,和查詢字符串一一進行Levenshtein edit distance或Jaccard index的計算, 若滿足閾值條件則添加到存放結果的向量。
Tournament sort
採用filter-and-verification framework,代碼中實現了索引、Filter和Verification三個部分。
索引
索引的數據結構是若干倒排索引,另外有一個hash table爲Q-gram到倒排索引的映射。
執行createIndex構建索引時,
對於每個輸入的字串,使用類似Rabin-Karp string
search算法的方式,獲取當前長爲
輸入文件讀入完畢後,對於hash table中的每個倒排索引(必然是非空的),在末端加入作爲哨兵元素的無窮大。
Filter
對於一個查詢,使用類似構建索引時的Rabin-Karp string search
algorithm,對於每個長爲
建立binary heap
列表
Tournament sort進行N-way merge
堆頂指針指向的值爲
,若old爲無窮大則返回 計算堆頂元素指向的值
的出現次數,若大於等於閾值 則添加到候選集中 把堆頂元素指針向前移動一格(即指向對應的倒排索引的下一項),若下一項仍等於原來指向的值則繼續移動
上述操作後堆頂指針指向的值變大了,對它進行下濾操作
若新的堆頂指向的值等於
則跳轉到步驟3
之後對候選集的每個元素進行檢驗,是否滿足Jaccard index或Levenshtein編輯距離的閾值要求, 輸出篩選後的。
Verification
Levenshtein edit distance
對於searchED操作,需要對每個候選字串和查詢字串計算編輯距離。
兩個字符串的Levenshtein edit distance可以使用
注意到代碼中使用到編輯距離的地方都有閾值
另外當其中某個字符串的長度小於等於128時,還可以採用bit
vector的算法@edit03加速到
Jaccard index
採用scan count的方式。 先用rolling hash計算查詢串所有Q-gram的標號,在計數容器中增加一。然後對於候選串的所有Q-gram,若計數容器中的值大於零則減去零並加到答案中。再便利候選串的所有Q-gram,把減去的值再加回來。
MergeSkip
和tournament sort基本結構相同,對Filter部分做了優化,即優化了統計每個字串的出現次數,過程如下:
堆頂指針指向的值爲
,若old爲無窮大則返回 計算堆頂元素指向的值
的出現次數,若大於等於閾值 則添加到候選集中 把堆頂元素指針向前移動一格(即指向對應的倒排索引的下一項),若下一項仍等於原來指向的值則繼續移動
上述操作後堆頂指針指向的值變大了,對它進行下濾操作
若新的堆頂指向的值等於
則跳轉到步驟3 從堆中彈出
個元素,使用二分檢索把這些倒排索引指針移動至大於當前堆頂指向的值,再重新插入堆中
DivideSkip
結合了MergeSkip和MergeOut。
使用啓發函數把倒排索引劃分爲長索引和短索引兩類,長索引有
個,其中 爲索引個數 對短索引採用MergeSkip算法,對於短索引中所有出現次數不少於
的元素,在所有長索引中二分檢索 將出現次數不少於
的元素添加到候選集中 把堆頂元素指針向前移動一格(即指向對應的倒排索引的下一項),若下一項仍等於原來指向的值則繼續移動
上述操作後堆頂指針指向的值變大了,對它進行下濾操作
若新的堆頂指向的值等於
則跳轉到步驟4 從堆中彈出
個元素,使用二分檢索把這些倒排索引指針移動至大於當前堆頂指向的值,再重新插入堆中
其他
Tournament類使用了curiously recurring template pattern。
Similarity join
任務
實現similarity join,近似串有兩種度量方式:Levenshtein edit
distance和Jaccard
index。需要實現SimJoiner類的joinED、joinJaccard兩個方法。
BruteForce
枚舉
DivideSkip
執行
索引
索引的數據結構是若干倒排索引,另外有一個hash table爲Q-gram到倒排索引的映射。
執行createIndex構建索引時,
對於每個輸入的字串,使用類似Rabin-Karp string
search算法的方式,獲取當前長爲
輸入文件讀入完畢後,對於hash table中的每個倒排索引(必然是非空的),在末端加入作爲哨兵元素的無窮大。
Filter
對於一個查詢,使用類似構建索引時的Rabin-Karp string search
algorithm,對於每個長爲
建立binary heap
列表
Tournament sort進行N-way merge
堆頂指針指向的值爲
,若old爲無窮大則返回 計算堆頂元素指向的值
的出現次數,若大於等於閾值 則添加到候選集中 把堆頂元素指針向前移動一格(即指向對應的倒排索引的下一項),若下一項仍等於原來指向的值則繼續移動
上述操作後堆頂指針指向的值變大了,對它進行下濾操作
若新的堆頂指向的值等於
則跳轉到步驟3
之後對候選集的每個元素進行檢驗,是否滿足Jaccard index或Levenshtein編輯距離的閾值要求, 輸出篩選後的。
使用啓發函數把倒排索引劃分爲長索引和短索引兩類,長索引有
個,其中 爲索引個數 對短索引採用MergeSkip算法,對於短索引中所有出現次數不少於
的元素,在所有長索引中二分檢索 將出現次數不少於
的元素添加到候選集中 把堆頂元素指針向前移動一格(即指向對應的倒排索引的下一項),若下一項仍等於原來指向的值則繼續移動
上述操作後堆頂指針指向的值變大了,對它進行下濾操作
若新的堆頂指向的值等於
則跳轉到步驟4 從堆中彈出
個元素,使用二分檢索把這些倒排索引指針移動至大於當前堆頂指向的值,再重新插入堆中
Verification
Levenshtein edit distance
需要對每個候選字串和查詢字串計算編輯距離。
兩個字符串的Levenshtein edit distance可以使用
注意到代碼中使用到編輯距離的地方都有閾值
另外當其中某個字符串的長度小於等於128時,還可以採用bit
vector的算法@edit03加速到
兩個字符串的Levenshtein edit
distance的下界是字符集所有字符出現頻數差的絕對值的和的一半,當該下界小於等於閾值時再進行實際計算。可以用_mm_sad_epu8來估算頻數差的絕對值的和。當某個字符頻數差大於等於256時會低估實際值,但對結果沒有影響。
Jaccard index
採用scan count的方式。 先用rolling hash計算查詢串所有Q-gram的標號,在計數容器中增加一。然後對於候選串的所有Q-gram,若計數容器中的值大於零則減去零並加到答案中。再便利候選串的所有Q-gram,把減去的值再加回來。
ppjoin@ppjoin
之前一個疑惑是沒理解similarity join和執行若干次similarity search有什麼區別。 原來是similarity search構建的索引能支持閾值不同的查詢,而similarity join直接指定了固定閾值, 因此構建的索引可以利用這個性質。
Prefix filtering
按照一個全序排序entity包含的gram,那麼若兩個串的overlap滿足:
Jaccard index轉化爲overlap
由
另由$ J(x,y) t
如果需要能所探尋到所有overlap超過
論文中沒有提及某gram被同一個entity包含多次的情況。這時
ppjoin
對於查詢串
需要一種類似數組的數據結構支持三種操作:清零、訪問某一項、列出上次清零以來所有訪問過的項。可以用三個數組和一個計數器實現。
Positional filtering
根據overlap計算hamming distance上界後根據
當gram有重複時比較麻煩,SuffixFilterWeighted中不能直接用mid作爲mid相同的字符。
對於可能重複的gram,另一種處理方式是讓各gram取不同的值。
Approximate entity extraction
任務
實現近似抽取,近似串有兩種度量方式:Levenshtein edit
distance和Jaccard index。
需要實現AEE類的createIndex、aeeED、aeeJaccard三個方法。
Faerie algorithm
實現採用@faerie中提到的Faerie algorithm。
索引
讀入描述entity的文件採用mmap:
1 | struct stat s; |
其中的MAP_POPULATE是爲了讓產生read-ahead的效果,加速文件讀入。
索引的數據結構包含:
entity向量
e把Q-gram映射爲entity編號的若干倒排索引
s2gid。若干倒排索引
gid2e,爲每個entity中出現的Q-gram保存包含該Q-gram的entity向量。
對於每個輸入的字串,使用類似Rabin-Karp string
search算法的方式,獲取當前長爲
s2gid的每個倒排索引末尾添加哨兵元素INT_MAX。
近似抽取
Levenshtein edit distance和Jaccard index均可用Faerie算法處理。對於每個文檔執行一次single-heap based algorithm。
建立binary heap
首先把長度爲doc劃分爲s2gid映射後得到L。
Tournament sort進行N-way merge得到候選子串
令
如果是Levenshtein edit distance查詢,則設置
記堆頂元素爲
eeid,彈出所有等於eeid的元素得到@faerie中的。 由於位置爲第二關鍵字,得到的
以及有序了。 使用尺取法尋找包含
中至少 個元素,且包含的Q-gram數在區間 內的所有窗口。 每個窗口可以產生若干候選子串。
代碼使用了batch-count pruning,使用尺取法時可以用@faerie中提到的二分檢索方法,一次把指針移動若干步。
Verification
之後對每個候選子串進行檢驗,是否滿足Jaccard index或Levenshtein編輯距離的閾值要求。
Levenshtein edit distance
兩個字符串的Levenshtein edit distance可以使用
注意到代碼中使用到編輯距離的地方都有閾值
另外當其中某個字符串的長度小於等於128時,可以使用內置類型__int128採用bit
vector的算法@edit03加速到
兩個字符串的Levenshtein edit
distance的下界是字符集所有字符出現頻數差的絕對值的和的一半,當該下界小於等於閾值時再進行實際計算。可以用_mm_sad_epu8來估算頻數差的絕對值的和。當某個字符頻數差大於等於256時會低估實際值,但對結果沒有影響。
Jaccard index
計算兩個串
採用scan count的方式計算s2gid計算查詢串所有Q-gram的編號,在計數容器中增加一。然後對於候選串的所有Q-gram,若計數容器中的值大於零則減去零並加到答案中。再遍歷候選串的所有Q-gram,把減去的值再加回來。
Trie-based@taste
令Levenshtein編輯距離閾值爲
若文檔
當探測到文檔的某子串
即需要把
多個串共同包含
多個串共同包含
把trie節點中檢索到的entity按
構建下層trie比較耗空間,可以借鑑suffix
array的思路,把索引到的entity的右側部分
另外如果發現計算到
生成結果
把匹配某個
文檔的某個子串和某個
Aho-Corasick automaton
目前的方式是對於文檔的每個位置都對上層trie探測得到候選entity,可以Aho-Corasick automaton改進。 注意Aho-Corasick automaton和Aho-Corasick algorithm的區別,前者會把trie改造爲圖(一些網絡資料稱之爲trie圖)。探測的文檔子串的右邊界在不斷增加,左邊界要根據Aho-Corasick狀態的轉移選擇性變化。
1 | TrieNode *p = trie_root, *q; for (int i, j = 0; j < m; ) { |
對於每個匹配的p都要沿着p->pi->pi->…鍊上溯到根。可以對於每個trie節點記錄其最長的表示一個pi的若干次冪)。這樣可以被多串匹配部分的複雜度從
演化
Faerie 7.263 Faerie+ED共用 4.197 Trie-based初版 2.4s 使用Aho-Corasick automaton後2.264s 利用公共前綴後 2.133s
實現空間數據庫的即敲即得式檢索系統
實驗要求
實現空間數據庫的即敲即得式檢索系統
給定100w個POI,以及一個查詢,找到所有的相關結果
基於位置的檢索和即敲即得式檢索
運行方式
項目由兩部分組成,實現檢索算法的部分爲後端,由C++11編寫; Web展示部分由網頁前端和Ruby Sinatra寫的web服務器組成。
運行後端:
1 | g++ -std=c++11 -O3 src/a.cc -ljsoncpp -o a |
將會讀取當前目錄下的zipcode.json並監聽TCP 1337端口。
運行web服務器:
1 | ruby web/web.rb |
將會監聽0.0.0.0:4567。
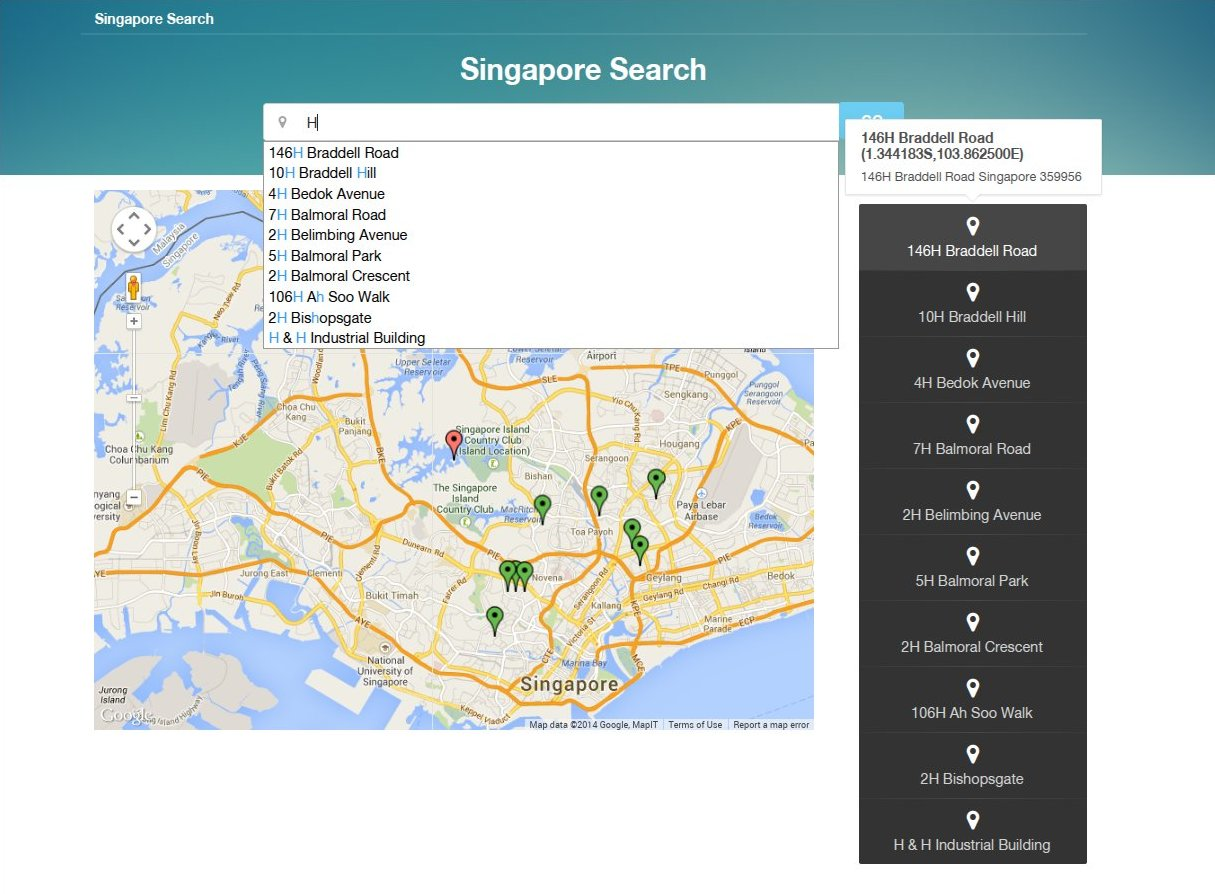
使用說明
瀏覽器打開,在輸入框中填寫字串name
字段包含字串
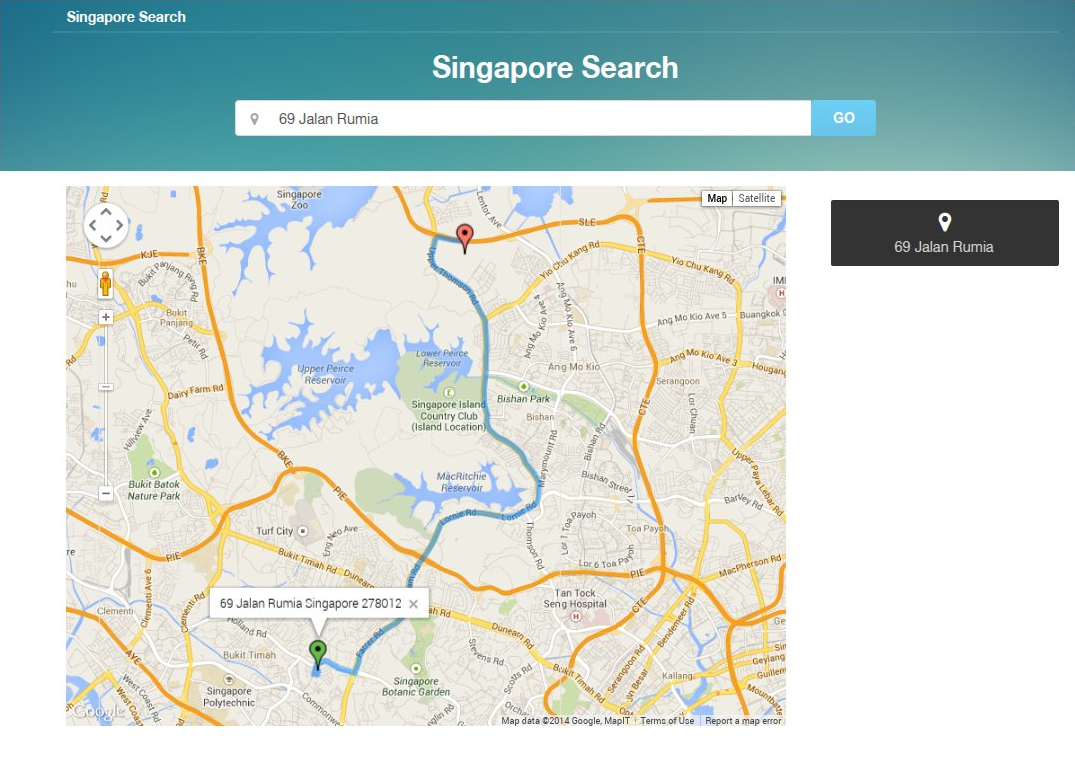
點擊marker或者代表候選地點的右側按鈕, 即可顯示起點到該地點的路徑。
項目實現
JSON輸入文件處理
輸入文件爲JSON格式的zipcode-address.json,後端程序使用C++庫JsonCpp進行JSON的解析和渲染。
位置檢索
根據實驗要求,location-aware instant search的方法直觀上是最適合的。但考慮到數據規模和prefix-region tree的描述,及想要實現任意子串而非單單前綴的查詢,我在項目中分別實現了位置檢索和地名檢索。
位置檢索屬於multidimensional spatial data structure的應用。考慮到我們需要處理的詢問:求出矩形區域內的地點和與給定點最近的k個地點,解決這類問題最常用的數據結構是R-tree家族。
R-tree
R-tree是派生於B+-tree的層次化數據結構,存儲d維點或矩形,一般的物體可以轉化爲最小包圍盒後用矩形的方式存儲。
R-tree除根以外的節點度限製爲
R-tree的操作通常用自頂向下遍歷,根據查詢和包圍盒的相關性來剪枝。 R-tree的缺點是分解是數據相關的,很難進行集合論操作比如交集。
Bulk loading
很多應用數據是靜態的,或者修改不頻繁,即使是動態的也很有可能很多數據可以提前知道。這時一次插入一項會帶來較大的加載代價,空間利用也不充分,結構不夠好。此時進行根據輸入數據特點進行bulk loading即建立初始數據結構是比較好的選擇。
R-tree bulk loading的通用的算法是:
把矩形劃分爲
個分組,每個分組爲一個葉節點。最後一個分組分配到的矩形可能不到 個。 遞歸地把若干個節點合併爲一個上一層的大節點,直到根節點被創建。
一種比較好的啓發式合併算法是Sort-Tile-Recursive。
Priority R-tree
@prtree是一種R-tree變體,window
query的時間複雜度爲
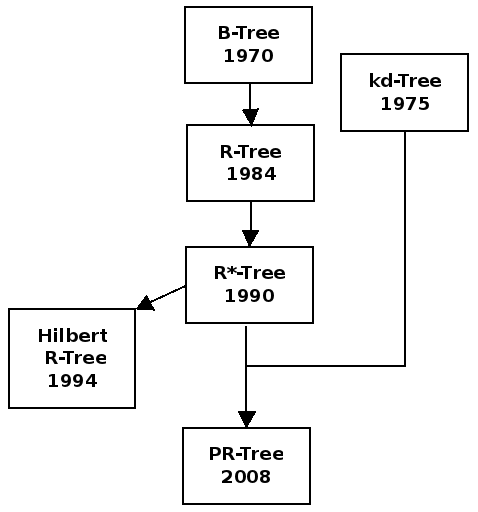
Priority R-tree算法實際上指的是R-tree的一種bulk loading算法。 Priority R-tree的構建爲若干次pseudo priority R-tree構建過程。
Pseudo priority R-tree的構建方式如下:
Extract B left-extreme points. Store them in a leaf-node.
Extract B bottom-extreme points. Store them in a leaf-node.
Extract B right-extreme points. Store them in a leaf-node.
Extract B top-extreme points. Store them in a leaf-node.
Partition the remaining n - 4B nodes into two halves based on our current tree depth, using the same scheme as found in the kd-tree data structure:
If ((depth % 4) == 0) partition by the x-coordinate (left-extreme).
If ((depth % 4) == 1) partition by the y-coordinate (bottom-extreme).
If ((depth % 4) == 2) partition by the x-coordinate in reverse (right-extreme).
If ((depth % 4) == 3) partition by the y-coordinate in reverse (top-extreme).
Recursivly apply this algorithm to create two sub-trees on the partitioned halves.
Stop when no points remain to be indexed (e.g. stop when n - 4B ≤ 0).去除pseudo priority R-tree的內部節點,把葉節點看作物體繼續調用pseudo
priority
R-tree進行下一輪構建,得到的內部節點再進行構建,如此反覆直到葉節點數
我的實現參考了一個Java版的priority R-tree實現:https://github.com/dshanley/prtree。
K-nearest neighbors
採用best-first search實現k-nearest neighbors問題,以距離的下界作爲估價函數。
地名檢索
C++後端實現了給出一個字串,輸出所有包含該字串的地點的功能。這個需求可以轉化爲string search問題。
Suffix array構建
Suffix array是解決string search問題的一個工具,它是一個字串所有後綴的排序。
線性時間的構建算法主要有Kärkkäinen-Sanders(@dc3)、Ko-Aluru(@ka)、KSP三種,其中KSP算法使用了類似suffix
tree的構建方式, Kärkkäinen-Sanders算法時間複雜度的遞推式爲
項目中我實現了Ko-Aluru算法,並按照@yangzhe的註記,借鑑@nzc對LMS substring遞歸排序使用的方法,對原始的Ko-Aluru算法進行改動以簡化內存使用和提升性能。我的實現在字串和suffix array外僅使用兩個數組:計數排序使用的桶和一個表示L/S類型的數組,反映了Ko-Aluru算法能達到和@nzc同等的精簡內存佔用。
Ka-Aluru suffix array construction algorithm
規定
令字符集爲
並結合以上兩種分類定義:
對於
Suffix array即爲
根據@ka的induced sorting,只要確定了
下面考慮如何遞歸求出
對於兩個長度不同的--substring
根據以上比較方式可以發現如果取出
先用桶排序求出所有-類型字符的大小,使用一次induced
sorting根據-計算 +,這樣便得到了所有形如
對--substring計算新字符集大小,若小於--substring數目則說明所有
--substring的順序已經確定,否則取出-字符遞歸計算suffix
array。得到這些--substring的順序即
實現技巧
整個實現分爲幾個階段,仍然設
計算
數組,需要使用 使用兩次induced sorting計算--substring的大小,需要使用
根據--substring構建新字串遞歸計算子suffix array
根據子suffix array計算
部分的suffix array 使用induced sorting根據
部分的suffix array得到整體suffix array
其中第2、3步需要特別使用了很多技巧節省空間佔用。
注意到
遞歸也需要使用
多數文獻都在
爲-,因爲把哨兵字符看作字典序最小。 根據+-substring計算--substring的induced sorting過程提前把
放入桶中。 否則因爲它是最後一個字符,無法被放入桶中,當該字符的桶包含兩個或更多元素時可能會導致它的位置被覆蓋而出錯。 計算新字符集時,需要注意比較過程中到達邊界的情況。
使用suffix array檢索字串
把所有地點的名字拼接爲一個字串後檢索字串的問題就轉化爲找到所有包含該字串的位置。在suffix
array中檢索所有長爲
1 | def search(P): |
String search可以用suffix tree的top-down traversal輕易實現。 @sa04提出了使用lcp表增強suffix
array的功能,從而實現
childtab
其性質是後綴
滿足
根據這些
\begin{aligned}
\text{up}[i] &=& \min{\{ q \in [0,i) | \text{lcp}[q] > \text{lcp}[i] \text{ and } \forall k\in [q+1,i): \text{lcp}[k]\geq \text{lcp}[q]\}} \\
\text{down}[i] &=& \min{\{ q \in [i+1,n) | \text{lcp}[q] > \text{lcp}[i] \text{ and } \forall k\in [i+1,q): \text{lcp}[k] > \text{lcp}[q]\}} \\
\text{next}[i] &=& \min{\{ q \in [i+1,n) | \text{lcp}[q] = \text{lcp}[i] \text{ and } \forall k\in [i+1,q): \text{lcp}[k] > \text{lcp}[i]\}} \\\end{aligned}last = -1
push(0)
for i = [1,n)
while lcp[i] < lcp[top]
last = pop
if lcp[i] <= lcp[top] && lcp[st] != lcp[last]
down[top] = last
if last != -1
up[i] = last
last = -1
push(i)
while 0 < lcp[top]
last = pop
if lcp[top] != lcp[last]
down[top] = last
if last != -1
up[n] = last
push(0)
for i = [1,n)
while lcp[i] < lcp[top]
pop
if lcp[i] == lcp[top]
next[top] = i
pop
push(i)有些項沒有值,不妨設爲無效值
用一個數組child表示
如果
對於一個可分割的
進一步,有多個區間終點相同,它們計算子區間要用到
其中、
表示
: -1 < child[i] && child[i] <= i表示
: child[i] > i && lcp[child[i]] > lcp[i]表示
: child[i] > i && lcp[child[i]] == lcp[i]
比如要在suffix array中搜索needle,@sa04中的僞代碼沒有考慮越界,修正如下:
found = true
(l, h) = get_interval(0, n, s[0])
i = 1
while found && i < m
if l < h-1
j = min(get_lcp(l, h), m)
found = a[sa[l]+i...sa[l]+j] == needle[i...j]
i = j
if i < m
(l,h) = get_interval(l, h, s[i])
else
found = a[sa[l]+i...sa[l]+m] == needle[i...m]
i = m
return found ? (l, h) : (-1, -1)如果要輸出方案,那麼複雜度變爲
得到包含needle的區間後,根據rank得到原字符串中的位置,即可知道哪些地點包含該字串。
結果呈現
前端
前端使用Slim作爲HTML的模板引擎,Sass爲CSS預處理器,CoffeeScript爲JavaScript預處理器,使用Semantic-UI CSS框架。Model和view的綁定採用了Model View ViewModel設計模式的 knockout.js。
Web服務器
項目中實現了基於Ruby的Sinatra實現了一個web
server:web/web.rb。
對於地圖點擊,前端將用ajax向web服務器提交請求,web/web.rb收到查詢請求後會使用TCP
socket向後端的C++服務器發送請求,
C++服務器進行位置檢索,web服務器得到應答後以JSON格式發送給前端,前端再進行處理。
自動補全的實現方式類似。前端的jquery-autocomplete發現輸入框內容改變後向web服務器提交ajax請求,web/web.rb收到查詢請求後使用TCP
socket向後端的C++服務器發送請求,C++服務器使用suffix
array進行地名檢索。
結果展示