存儲層次分析及程序優化
測試環境
系統
使用的機器CPU爲Intel(R) Core(TM) i5-3317U CPU @ 1.70GHz,可以在cpu-world.com上查到各級cache大小,L1
data cache爲32KiB,L2 cache爲256KiB,L3 cache爲3072KiB。
編譯器
% gcc -v
Using built-in specs.
COLLECT_GCC=/usr/x86_64-pc-linux-gnu/gcc-bin/4.8.2/gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-pc-linux-gnu/4.8.2/lto-wrapper
Target: x86_64-pc-linux-gnu
Configured with: /var/tmp/portage/sys-devel/gcc-4.8.2-r1/work/gcc-4.8.2/configure --host=x86_64-pc-linux-gnu --build=x86_64-pc-linux-gnu --prefix=/usr --bindir=/usr/x86_64-pc-linux-gnu/gcc-bin/4.8.2 --includedir=/usr/lib/gcc/x86_64-pc-linux-gnu/4.8.2/include --datadir=/usr/share/gcc-data/x86_64-pc-linux-gnu/4.8.2 --mandir=/usr/share/gcc-data/x86_64-pc-linux-gnu/4.8.2/man --infodir=/usr/share/gcc-data/x86_64-pc-linux-gnu/4.8.2/info --with-gxx-include-dir=/usr/lib/gcc/x86_64-pc-linux-gnu/4.8.2/include/g++-v4 --with-python-dir=/share/gcc-data/x86_64-pc-linux-gnu/4.8.2/python --enable-languages=c,c++,fortran --enable-obsolete --enable-secureplt --disable-werror --with-system-zlib --enable-nls --without-included-gettext --enable-checking=release --with-bugurl=https://bugs.gentoo.org/ --with-pkgversion='Gentoo 4.8.2-r1 p1.4-ssptest, pie-0.5.9-ssptest' --enable-libstdcxx-time --enable-shared --enable-threads=posix --enable-__cxa_atexit --enable-clocale=gnu --enable-multilib --with-multilib-list=m32,m64 --disable-altivec --disable-fixed-point --enable-targets=all --disable-libgcj --enable-libgomp --disable-libmudflap --disable-libssp --enable-lto --without-cloog
Thread model: posix
gcc version 4.8.2 (Gentoo 4.8.2-r1 p1.4-ssptest, pie-0.5.9-ssptest)編譯選項爲:export CXXFLAGS=’-std=c++11 -g -O3 -march=native’
查看cache信息也可以使用如下方法:
sysconf
獲取L1 cache line大小:
% getconf LEVEL1_DCACHE_LINESIZE
64dmidecode
查看系統的DMI信息,可以發現兩個32K的L1 cache分別是數據cache和指令cache。
L1 data cache的相連度爲8,大小爲32KiB。
L2 cache的相連度爲8,大小爲256KiB。
% sudo dmidecode -t cache
# dmidecode 2.12
SMBIOS 2.7 present.
Handle 0x0005, DMI type 7, 19 bytes
Cache Information
Socket Designation: L1 Cache
Configuration: Enabled, Not Socketed, Level 1
Operational Mode: Write Through
Location: Internal
Installed Size: 32 kB
Maximum Size: 32 kB
Supported SRAM Types:
Unknown
Installed SRAM Type: Unknown
Speed: Unknown
Error Correction Type: Parity
System Type: Data
Associativity: 8-way Set-associative
Handle 0x0006, DMI type 7, 19 bytes
Cache Information
Socket Designation: L1 Cache
Configuration: Enabled, Not Socketed, Level 1
Operational Mode: Write Through
Location: Internal
Installed Size: 32 kB
Maximum Size: 32 kB
Supported SRAM Types:
Unknown
Installed SRAM Type: Unknown
Speed: Unknown
Error Correction Type: Parity
System Type: Instruction
Associativity: 8-way Set-associative
Handle 0x0007, DMI type 7, 19 bytes
Cache Information
Socket Designation: L2 Cache
Configuration: Enabled, Not Socketed, Level 2
Operational Mode: Write Through
Location: Internal
Installed Size: 256 kB
Maximum Size: 256 kB
Supported SRAM Types:
Unknown
Installed SRAM Type: Unknown
Speed: Unknown
Error Correction Type: Multi-bit ECC
System Type: Unified
Associativity: 8-way Set-associative
Handle 0x0008, DMI type 7, 19 bytes
Cache Information
Socket Designation: L3 Cache
Configuration: Enabled, Not Socketed, Level 3
Operational Mode: Write Back
Location: Internal
Installed Size: 3072 kB
Maximum Size: 3072 kB
Supported SRAM Types:
Unknown
Installed SRAM Type: Unknown
Speed: Unknown
Error Correction Type: Multi-bit ECC
System Type: Unified
Associativity: 12-way Set-associativesysfs
另外也可以查看sysfs:
% for i in /sys/devices/system/cpu/cpu0/cache/*; do echo -- $i; cat $i/{type,size,ways_of_associativity}; done
-- /sys/devices/system/cpu/cpu0/cache/index0
Data
32K
8
-- /sys/devices/system/cpu/cpu0/cache/index1
Instruction
32K
8
-- /sys/devices/system/cpu/cpu0/cache/index2
Unified
256K
8
-- /sys/devices/system/cpu/cpu0/cache/index3
Unified
3072K
12測量方法
步長均以字節爲單位。
分配一個大小和測試項目有關的數組,以特定步長順序訪問,訪問完後從首元素開始繼續訪問(即循環順序訪問)。
雙層循環
其中一種實現方式是內外兩層循環,內循環執行次數和數組大小與步長相關,外循環執行次數根據內循環執行次數計算得到,控制訪問總次數固定。代碼如下:
1 | int a[...], k; |
其中volatile是爲了保證向z的存儲位置寫入值,從而防止k的計算被優化掉。
單循環,兩個循環變量
上面方法的問題在於對於不同的數組大小和步長,內循環執行次數不同。在固定循環次數的情況下,內循環較大的效率略高。爲了減少干擾,我們應該儘量使用單循環。
我們可以使用一個變量控制循環次數,另一個變量控制訪問的數組索引。考慮到測試的數組大小、步長等都是2的冪,可以使用位與把數組索引限制在有效範圍內:
1 | for (unsigned j = 0, i = ITERS; i > 0; j += s, i--) |
其中mask是數組大小減一
使用1-tree設計僅含三條彙編指令的單循環
如果把數組元素設想爲節點,值看作索引作爲指向其他元素的指針,數組可以看作是多個1-tree形成的pseudoforest。比如設計這樣一個包含0的1-tree:a[0]==16, a[16]==32, ..., a[96]==0。
按如下方式設計循環體:
1 | int k = 0; |
g++ -O3編譯可以發現得到瞭如下指令:
401240: 83 e8 01 sub eax,0x1
401243: 8b 14 91 mov edx,DWORD PTR [rcx+rdx*4]
401246: 75 f8 jne 401240 <_Z10cache_sizev+0x1d0>僅包含三條指令。 如果把cache miss的代價視爲常數,那麼儘量減少每輪迭代裏其他開銷可以凸顯cache miss的損失。
在測量cache大小時發現採用這種循環方式確實cache miss顯示得更清楚了,但是L2 cache的miss就不明顯了:
另外索引的變化方式似乎變得不易預測了,效率變低了一些。
其他
數組按照L2 cache大小和頁大小的倍數對齊比較好。
可以使用aligned_alloc或posix_memalign等函數,代碼中按4MiB對齊。
另外數組分配完後,在測試前需要修改各頁以防止demand paging對測量結果造成影響。
Cache大小測量
策略
數組大小從4KiB開始翻倍,每次間隔16個元素順序訪問,測量重複若干次的訪問時間。
設計原理
順序訪問兩倍cache大小的數組會導致任何cache替換策略都全部miss。數組大小每次都擴大一倍看訪問時間,當時間突然增加時就表示當前的數組大小已經超過目前考察的某層次cache的大小了。
因爲hardware prefetching@prefetch的存在,數組訪問的索引步長不能太小。另外固定數組訪問次數測評時,如果索引步長較小,那麼cache miss的比例也會降低,使得相應的損失不夠顯著。
實驗結果
源文件爲src/a.cc
% ./a -c
stride(KB) time(s)
4 0.508398
8 0.494066
16 0.506885
32 0.504679
64 1.059095
128 1.077871
256 1.141273
512 1.422013
1024 1.447682
2048 1.694575
4096 3.108610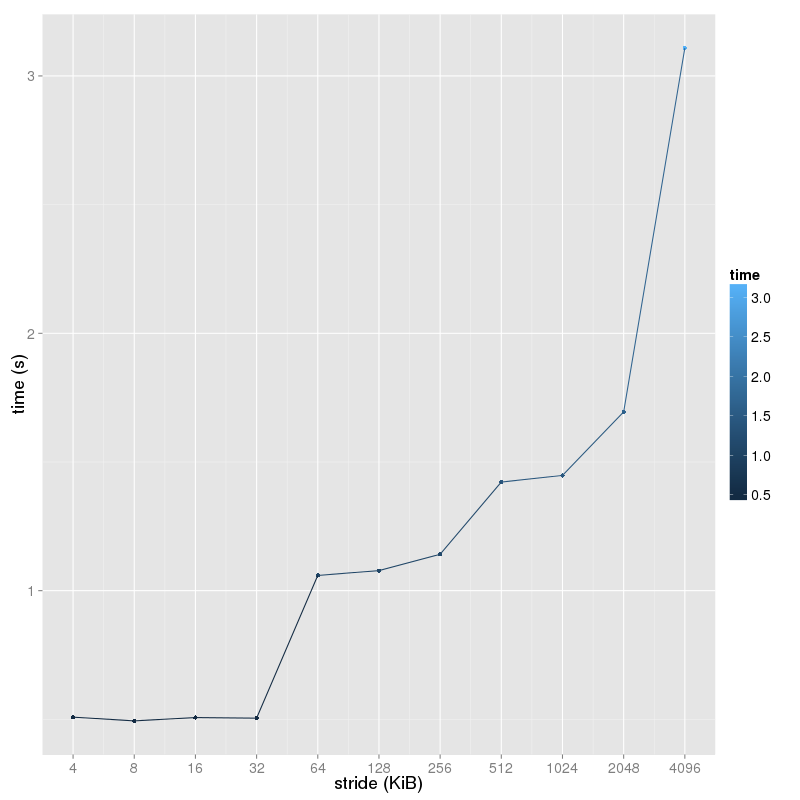
實驗數據分析
可以看出來在32KiB升64KiB、256KiB升512KiB、2048KiB升4096KiB處運行時間有較大的增幅,印證了L1 data cache爲32KiB,L2 cache爲256KiB,L3 cache在2048KiB和4096KiB之間。
代碼中我取stride爲256,實際測試發現當stride爲32時將無法發現32KiB升64KiB時的較大增幅,可能是因爲hardware prefetching的存在, 硬件檢測到了內存訪問的模式而進行了預存。
另一種策略
根據@cs519,上述方法採用了capacity miss的性質來測量cache大小,另外可以使用conflict miss。 類似於cache line大小的測量,當以cache size爲步長大小或更大的步長訪問時, 衝突會比較大,導致性能下降。
代碼中的cache_size_alternative實現了該方法,但未能印證cache大小。
Cache塊大小測量
策略
考察L1 cache時,數組大小設爲L1 cache大小的兩倍,以特定步長訪問數組。每次把步長倍增,當發現運行時間有較大增幅時表明步長已經大於等於cache line大小。
之後再把數組大小設爲L2 cache兩倍,做類似的測試。雖然L1 cache包含在L2 cache裏,但因爲比L2 cache小很多,造成的影響小於L2 cache miss的影響。所以如果L2 cache的塊大小不同,應該能看到另一處也有階梯狀現象。
設計原理
數組大小爲兩倍cache大小時,cache line會被不停地替換掉。一個cache
line可能可以容納多個元素,只有該cache
line的第一次元素訪問纔會miss,有較大代價, 之後的訪問會變快。當
實驗結果
% ./a -l 65536
stride(B) time(s)
4 0.254627
8 0.250141
16 0.252348
32 0.288567
64 0.532215
128 0.531537
256 0.529876
512 0.534260
% ./a -l 262144
stride(B) time(s)
4 0.252893
8 0.254049
16 0.256715
32 0.295765
64 0.591509
128 0.595276
256 0.586291
512 0.582670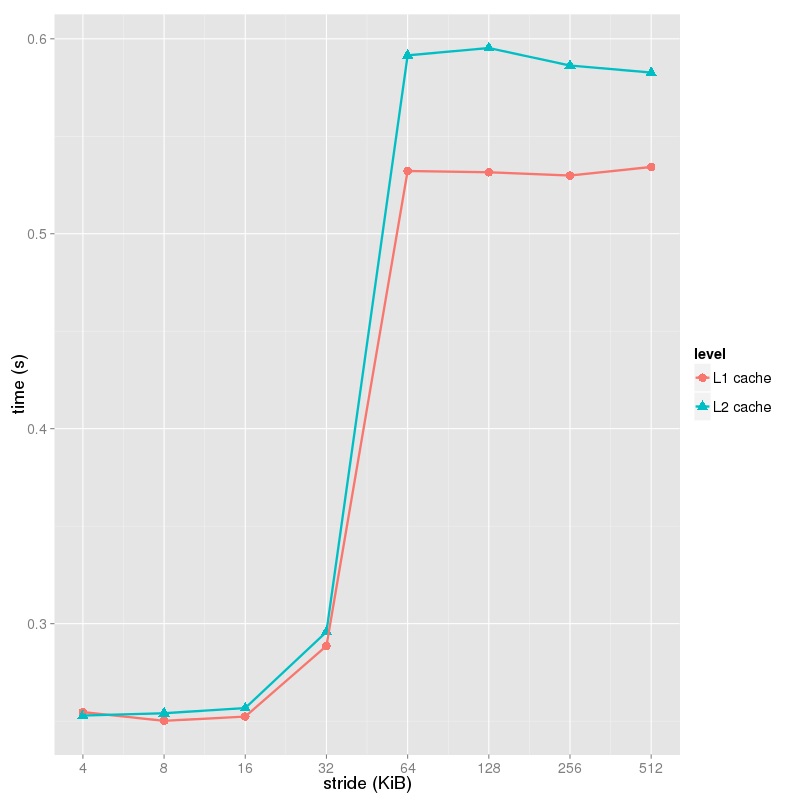
實驗數據分析
對64KiB的L1 cache大小,可以看到步長爲64時時間有較大增長,但之後趨於平穩,故cache line大小爲64字節。
對256KiB的L2 cache大小,可以看到步長爲64時時間有較大增長,但之後趨於平穩,故cache line大小爲64字節。
Cache相連度
策略
數組大小設置爲cache大小,然後每次倍增,以cache大小爲步長訪問,當一個循環內訪問的元素數大於等於set-associativity的兩倍時,上一次枚舉的ways就是set-associativity。
設計原理
以cache大小爲步長訪問時,每次訪問的元素的索引值都相同。當訪問的元素數大於等於set-associativity的兩倍時,就會保證每次訪問都會miss,從而時性能急劇下降,且上一次枚舉的ways就是所求。
實驗結果
% ./a -a $[32*1024]
ways time(s)
1 0.670270
2 0.669508
4 0.674767
8 0.673887
16 0.846521
32 1.409794
% ./a -a $[256*1024]
ways time(s)
1 0.670007
2 0.665101
4 0.670972
8 0.643787
16 2.684241
32 7.747577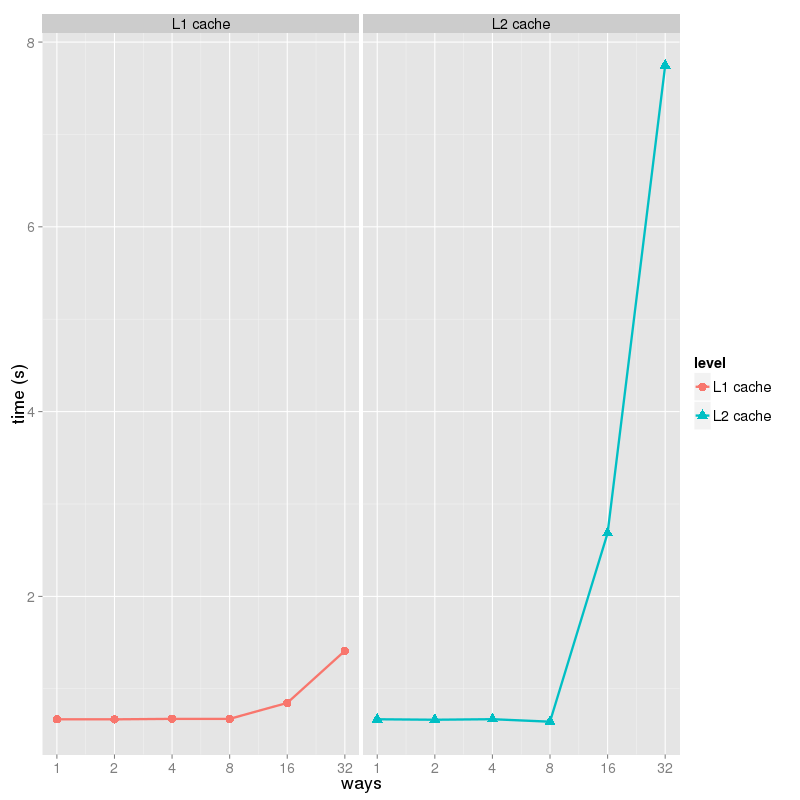
實驗數據分析
枚舉到16倍cache大小時,時間劇增,因此L1 data cache的相連度爲上一次枚舉的值:8。
枚舉到16倍cache大小時,時間劇增,因此L2 data cache的相連度爲上一次枚舉的值:8。
Cache寫回策略
策略
對於一倍和兩倍cache大小的數組,順序訪問測量時間,若近似相等則爲write-through,否則是write-back。
設計原理
write-through在寫入時一定會訪問內存,表現和all miss類似,所以可以比較兩種模式的運行時間。
實驗結果
% ./a -r $[32*1024]
hit 0.159024
miss 0.334086
% ./a -r $[256*1024]
hit 0.561438
miss 0.722406實驗數據分析
對於L1 L2 cache大小,兩種模式時間都有較大差異,故都是write-back。
Cache替換策略
設計原理
當數組大小剛好大於cache大小並且以循環順序模式訪問時,標準的LRU表現會像是all miss。
這裏的測試較爲困難,因爲兩種測試在代碼或數據上至少有一項不同,會有很多情況影響運行結果,很難設計反映LRU自身特性的測試。
實驗結果
% ./a -s
all miss 3.497159
lru miss 3.312766實驗數據分析
數組大小剛好大於cache大小並且以循環順序模式訪問時,實際時間比all miss略少,猜測CPU使用的不是標準的LRU算法。實際上Ivy-Bridge使用的是一種變化的LRU。
矩陣乘法優化
原始代碼分析
b[][])以column-major
order訪問,導致cache頻繁miss而性能低下。另外原來的代碼在我的Linux系統裏無法編譯通過,因爲缺少了cstring頭文件,源代碼的頭文件部分添加了。
考慮這樣一個tall ideal cache model: cache line大小爲
當
當
交換三層循環次序
通過把i,j,k的三層循環次序修改爲i,k,j能使其中兩個矩陣的都成爲row-major
order訪問, 提高了效率。代碼參見:src/matrix_mul.cpp。
對於
運行結果:
% ./matrix_mul
time spent for original method : 14909765 ms
time spent for new method : 803459 msk,i,j的循環次序也能提高效率,但效果略差於i,k,j,原因是d[i][j] += a[i][k] * b[k][j];中兩個數組的第一維是i,一個是k,對於i,k,j的循環次序,兩個數組更容易被緩存。
% ./matrix_mul
time spent for original method : 14682039 ms
time spent for new method : 1024053 ms另外使用icpc -O3編譯會發現原始版本也很快,改進效果很不明顯:
% icpc -v
icpc version 14.0.2 (gcc version 4.8.0 compatibility)
% ./matrix_mul
time spent for original method : 842223 ms
time spent for new method : 817969 ms查看icpc -O3 -opt-report的輸出可以發現:
<matrix_mul.cpp;38:38;hlo_linear_trans;main;0>
LOOP INTERCHANGE in loops at line: 40 42
Loopnest permutation ( 1 2 3 ) --> ( 1 3 2 )編譯器做了loop
interchange優化,把循環次序修改爲i,k,j。
測試了GCC的Graphite loop transformation
infrastructure,但是-floop-interchange似乎沒有起效。
轉置b使得b變爲column-major
order訪問
另外一種方式是在乘法前轉置b使得它的訪問變爲row
major順序,乘法後再轉置回來:src/matrix_mul_transpose.cpp。
當
運行結果:
time spent for original method : 14655990 ms
time spent for new method : 3795749 ms使用Intel VTune Amplifier
XE進行性能剖析發現swap的總開銷爲0.01秒,k所在循環執行時間爲3.780秒,而原來的方法的k循環執行時間爲12.926秒。轉置帶來的代價很小。另外這裏使用的轉置方法不是考慮cache的情況下最佳的,使用loop
tiling的方式會更好。
另外代碼使用到了algorithm頭文件的swap。
Cache-aware blocked matrix multiplication
這個方法應用了loop tiling的技巧,把原矩陣分割成若干個邊長爲
源代碼見src/matrix_mul_block.cpp。
% ./matrix_mul_block
time spent for original method : 14722019 ms
time spent for new method : 2165467 ms代碼中t += a[i][k] * b[k][j];是瓶頸,只涉及了兩個矩陣,因此可以取
我在CPU爲Intel(R) Xeon(R) CPU E3-1220 V2 @ 3.10GHz的服務器上測試不同塊大小
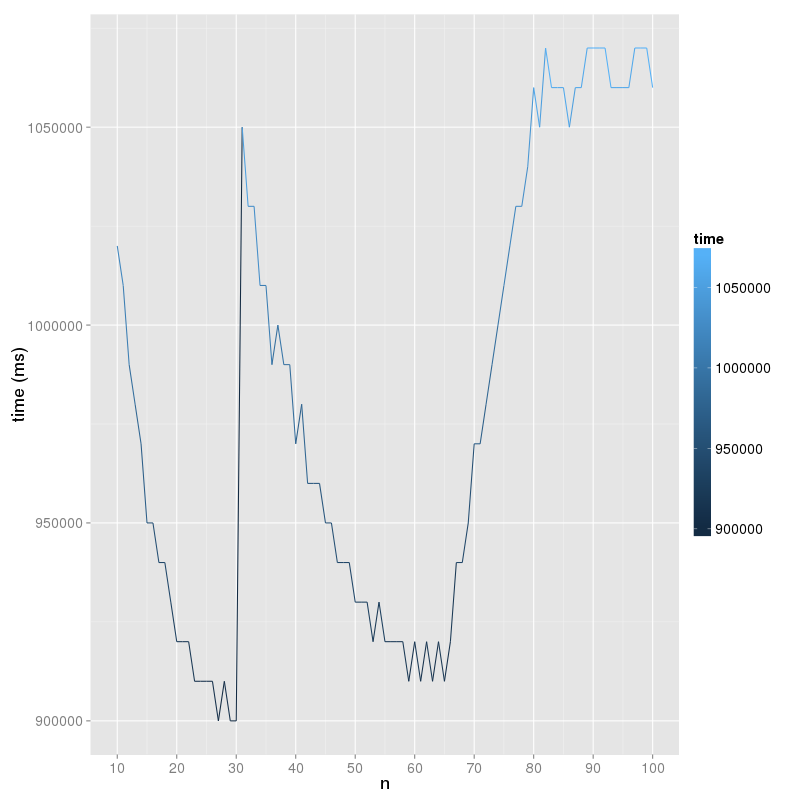
根據L1 cache大小(32KiB)計算出
擴展
對於其他更複雜的問題,cache-oblivious algorithm的寫法可能會更好。
矩陣用row-major order以外的方式存儲如von Emde Boas layout可能會更塊。
分支預測
預測方法概述
Static prediction
不依賴代碼執行歷史進行預測,比如根據opcode預測總是跳轉或不跳轉。一個比較好的方法是displacement based,預測後向跳轉總是發生,而前向跳轉總是不發生。另外還可以根據分支的可能性使用不同的指令,編譯器在生成代碼時生成不同的opcode提示CPU。
Saturating counter
常用2個bit記錄4個狀態,實現爲bimodal predictor,4個狀態分別表示:
Strongly not taken
Weakly not taken
Weakly taken
Strongly taken
每當分支結果產生,就用saturating的加減法操作更新計數器。如果跳轉則令計數器表示的可能性增大,即往下移動,不跳轉則往上移動。
使用2個bit而不是1個bit的好處在於常見的循環結構,如果條件跳轉在循環體後面,則後向跳轉比較多,該指令的歷史將是一串“跳轉”後跟一個“不跳轉”。計數器將很快表示strongly taken且即使碰到最後的“不跳轉”, 也只是把狀態變爲weakly taken,下次執行循環時人能正確預測。如果條件跳轉在循環體前面,則前向跳轉比較多,該指令的歷史將是一串“不跳轉”後跟一個“跳轉”,情況和後向跳轉類似。
Local branch prediction
對每條條件分支指令維護歷史狀態,預測時根據當前指令的歷史狀態進行預測。這種方式對數據存儲方式有較大要求,很容易佔用過多存儲空間。這個特徵的實用性較小,我看到的很多較好的預測器都不使用這個特徵。
Global branch prediction
所有條件分支指令共享一個保存歷史的緩衝區,歷史信息就是最近的若干次條件分支是否發生的bitset。
Path history based predictor
把最近執行的指令地址納入考慮範圍。如果取完整的地址會比較浪費,JWAC-2中André SSeznec的實現中取最近若干條指令地址的最低位的bitset作爲特徵,可以這麼做的原因是x86-64指令長度不規整。
Multiple branch histories
最初的基於global history的方式只使用一個表對某一特定長度的歷史進行預測,@mcfarling裏描述了一個使用多個歷史長度的預測器。
Neural branch prediction
有很多研究使用感知器搭建神經網絡進行分支預測,優點是很容易利用長歷史,但涉及到的串行運算較多(比如感知器涉及到兩個向量的乘積)會導致較大的延時。
Branch target prediction
預測器介紹
gshare
實驗框架中的默認預測器實現了@mcfarling中提到的gshare算法,從分類上說屬於two-level adaptive predictor,可以在緩衝區條目中區分不同分支指令的歷史,方法是把分支地址和global history異或後計算緩衝區的索引值。 索引得到的是saturating counter。比起直接用分支地址索引saturating counter,結合了global history後能更準確一些。
Idealized Piecewise Linear Branch Predictor
@daniel中描述的感知器,以當前條件分支前的各條分支指令和相隔距離,以及該分支自身的local history作爲特徵訓練感知器。 當前指令,與它產生相互作用的global history中的另一條指令,和它們的間隔有三維,狀態數很多, Daniel A. Jiménez的實現中分配了一個很大的數組儲存感知器的向量,把這三維hash後計算得到數組中的下標。這裏hash的下標沒有考慮衝突的情況,可能是基於兩個原因:
避免引入額外的存儲空間開銷。感知器的向量係數可以用一個字節或幾個比特表示,如果採用類似separate-chaining的方法,指針的引入將帶來極大的開銷。
延遲相比準確性更重要。如果採用open addressing這樣的方法,會增大延時,得不償失。
實現中還會根據訓練數據估測workload的類型,動態調整參數。另外一段時間後會清空訓練的感知器的向量,我覺得原因可能是程序通常具有階段性,不同階段的表現出入較大,作者是希望放置上一階段的訓練結果影響到之後階段的預測。但測試發現去除清空操作後效果更好。
Daniel A.
Jiménez的預測器簡單修改適配實驗框架後測試所有traces得到的平均MISPRED_PER_1K_INST值爲3.6。
TAGE
第二次實驗中我實現了@tage中描述的TAGE算法,這是一種PPM類型的預測器@ppm,由一個基礎分支預測器(採用saturating bimodal predictor)和若干個長度不同的PPM(prediction by partial matching)預測器組成。
每個PPM預測器有一個內置的長度
預測階段
預測時,找到內置長度最大的找得到匹配項的PPM預測器,令其saturating
counter指示的結果爲
如果
PPM檢索方式
PPM預測器的每個記錄項是(分支指令發生前history中最近
實現中每個PPM預測器根據其內置長度
Global history只記錄最近的若干條記錄。 設global history中第
令槽位的索引值爲gi>>i & 1的值定義爲
根據
更新階段
用當前條件跳轉指令是否發生跳轉來更新global history, 並把(global
history中最近
如果之前的最終預測結果(有兩種可能取值,
PPM根據地址和最近若干項global
history計算得到的tag(hash值)很可能會衝突。衝突時保留原來的項還是取新的項?爲此,每個條目還要記錄一個
每個PPM預測器條目還要保存一個
對於一個條目,如果之前有很多次預測以它爲
如果以它爲
當添加新項發生衝突時會考察已有項的
如前文所說,當
由於有
存儲需求
我的實現運行時會在stderr輸出空間佔用:
storage: 260348 bits = 32544 bytes其中包含了一些標量變量的空間佔用。
佔空間的主要是每個PPM預測器儲存的項,各個PPM預測器容量不盡相同,爲512項到2048項。
結果
LONG-SPEC2K6-00 1.531
LONG-SPEC2K6-01 7.510
LONG-SPEC2K6-02 0.364
LONG-SPEC2K6-03 0.575
LONG-SPEC2K6-04 8.590
LONG-SPEC2K6-05 4.911
LONG-SPEC2K6-06 0.635
LONG-SPEC2K6-07 9.259
LONG-SPEC2K6-08 0.670
LONG-SPEC2K6-09 3.628
LONG-SPEC2K6-10 0.670
LONG-SPEC2K6-11 0.670
LONG-SPEC2K6-12 11.498
LONG-SPEC2K6-13 6.131
LONG-SPEC2K6-14 0.001
LONG-SPEC2K6-15 0.332
LONG-SPEC2K6-16 3.278
LONG-SPEC2K6-17 2.487
LONG-SPEC2K6-18 0.057
LONG-SPEC2K6-19 1.082
SHORT-FP-1 1.226
SHORT-FP-2 0.518
SHORT-FP-3 0.018
SHORT-FP-4 0.094
SHORT-FP-5 0.029
SHORT-INT-1 0.146
SHORT-INT-2 4.927
SHORT-INT-3 8.000
SHORT-INT-4 0.563
SHORT-INT-5 0.301
SHORT-MM-1 7.282
SHORT-MM-2 9.359
SHORT-MM-3 0.070
SHORT-MM-4 1.161
SHORT-MM-5 4.413
SHORT-SERV-1 0.901
SHORT-SERV-2 0.872
SHORT-SERV-3 3.228
SHORT-SERV-4 2.301
SHORT-SERV-5 1.842
AMEAN 2.778而baseline程序的結果如下:
LONG-SPEC2K6-00 3.974 [2/1974]
LONG-SPEC2K6-01 8.406
LONG-SPEC2K6-02 5.176
LONG-SPEC2K6-03 5.658
LONG-SPEC2K6-04 10.739
LONG-SPEC2K6-05 5.780
LONG-SPEC2K6-06 4.160
LONG-SPEC2K6-07 14.062
LONG-SPEC2K6-08 1.911
LONG-SPEC2K6-09 5.502
LONG-SPEC2K6-10 3.710
LONG-SPEC2K6-11 3.929
LONG-SPEC2K6-12 12.844
LONG-SPEC2K6-13 9.880
LONG-SPEC2K6-14 4.687
LONG-SPEC2K6-15 2.648
LONG-SPEC2K6-16 4.435
LONG-SPEC2K6-17 5.464
LONG-SPEC2K6-18 1.525
LONG-SPEC2K6-19 2.599
SHORT-FP-1 3.479
SHORT-FP-2 1.061
SHORT-FP-3 0.443
SHORT-FP-4 0.258
SHORT-FP-5 0.788
SHORT-INT-1 7.347
SHORT-INT-2 7.669
SHORT-INT-3 11.784
SHORT-INT-4 2.250
SHORT-INT-5 0.438
SHORT-MM-1 9.172
SHORT-MM-2 10.601
SHORT-MM-3 4.267
SHORT-MM-4 1.811
SHORT-MM-5 5.651
SHORT-SERV-1 3.646
SHORT-SERV-2 3.665
SHORT-SERV-3 5.870
SHORT-SERV-4 5.324
SHORT-SERV-5 5.208
AMEAN 5.196