文本分類
算法描述
Naive Bayes classifier
採用multinomial Naive Bayes
model,文檔中單詞分佈視爲multinomial的,單詞之間相互沒有影響,文檔被歸入某一分類
實現中根據最大後驗概率把文檔歸入分類
取對數後得到:
實現中爲每個候選分類設置一個分數值,初始化爲該分類的先驗概率,之後對於查詢文檔中的每個詞,用
Support vector machine classifier
特徵選取:
預料中單詞總數約爲15000,根據
運行結果
準確率
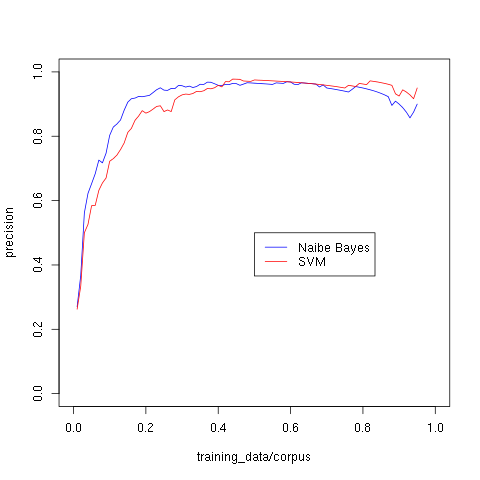
把測試數據劃分成訓練數據和測試數據,以訓練數據佔語料的比例爲橫軸,測試數據準確率爲縱軸繪得下圖:
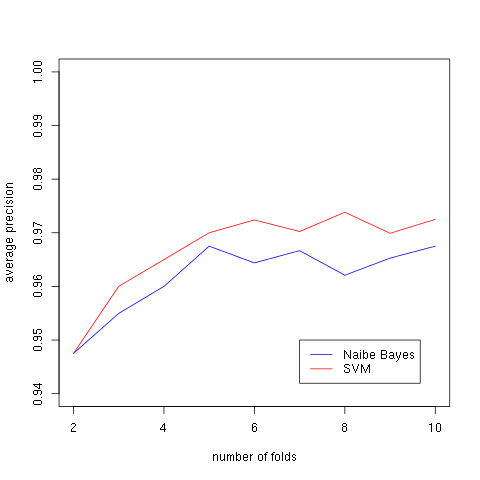
交叉驗證
實現
爲C++ 11實現,另有的OCaml實現。
執行即可編譯C++ 11實現,生成。
在程序執行的工作目錄創建文件表示訓練數據,其格式如下:
# hardware
/tmp/data/c4_comp.sys.mac.hardware/52446
/tmp/data/c4_comp.sys.mac.hardware/52439
/tmp/data/c4_comp.sys.mac.hardware/52342
# atheism
/tmp/data/c1_atheism/54258
/tmp/data/c1_atheism/54249
/tmp/data/c1_atheism/54163其中和代表分類名,之後的文件名則爲具體的訓練數據文件名。
再創建表示測試數據,比如:
# hardware
/tmp/data/c4_comp.sys.mac.hardware/52193
/tmp/data/c4_comp.sys.mac.hardware/52090
# atheism
/tmp/data/c1_atheism/51060
/tmp/data/c1_atheism/51119格式和相同。
運行即返回Naive Bayes分類的準確度。
運行即返回Naive Bayes分類的準確度,同時輸出每個測試數據的分類結果。
運行即返回SVM分類的準確度。
運行即返回SVM分類的準確度,同時輸出每個測試數據的分類結果。
四子棋
課程設計是實現四子棋AI。
算法描述
本次程序實驗中我使用了Monte Carlo Tree Search算法,這類算法把博弈樹搜索和隨機算法結合了起來, domain-specific knowledge是可選的,這意味着無需像minimax那樣實現一個對未結束局面估價的函數。
在每一回合收到getPoint指令後,程序建立一個根節點表示當前局面。每個節點連向孩子的邊代表處於該節點表示的局面下可以選擇的着法,而相應的孩子就是選擇該着法後轉移到的局面。樹一開始只包含根節點,在之後的expansion過程中節點會被添加到樹中。
然後執行若干次迭代過程,每次迭代都會依次執行selection、expansion、simulation和backpropagation四個過程。
Selection。從根出發,根據tree policy走到一個孩子節點,重複此過程直到碰到一個可擴展的節點爲止。可擴展的節點指的是帶有未訪問孩子的節點。
Expansion。此時我們已經走到了一個可擴展節點。根據tree policy選擇未探索過的着法中最有探索價值的,給當前節點添加一個孩子並走到這個孩子節點。
Simulation。根據default policy在當前節點表示棋盤下模擬雙方對弈。
Backpropagation。根據對弈的結果更新當前節點及其所有祖先的統計信息。
MCTS是這一類算法的統稱,通過選取適當的tree policy和default policy就得到了一系列具體算法。 對於tree policy,我使用了Upper Confidence Bounds for Trees(UCT)算法,根據公式:
來選擇具有最大
公式中第一個加數表示孩子節點的優秀程度(exploitation),第二個加數表示探索度(exploration)。
Exploitation高代表選擇該孩子節點對應的着法,模擬對弈的結果中有利局面多,所以該孩子節點對應的着法較爲優秀。
Exploration高代表選擇該孩子節點對應的着法的嘗試次數不夠多(因爲
在分母中),需要進一步探索。
優化
位棋盤
需要處理的最大棋盤規模爲uint64_t表示三列,那麼12列就只需要3個uint64_t來表示,可以看作一個uint192_t,其各個二進制位對應的棋盤上位置如下:
64-bit 64-bit 64-bit
0f 1f 2f 3f | 4f 5f 6f 7f | 8f 9f af bf
.. .. .. .. | .. .. .. .. | 8. 9. .. ..
01 11 21 31 | 41 51 61 71 | 81 91 a1 b1
00 10 20 30 | 40 50 60 70 | 80 90 a0 b0對於勝負的判定,只需要用移位操作和與運算即可在在w & w>>1 & w>>2 & w>>3,類似地可以判斷水平方向、斜線方向上是否連成四子。
另外,不儲存每一列的
快速log
改用https://github.com/herumi/fmath的實現後搜索性能有明顯提升。
省略父節點
父節點指針僅用於backpropagation過程,而這一過程中訪問到的祖先節點都在之前select步驟時訪問過了,所以可以用棧保存根節點到當前節點路徑上的所有節點,無需存儲父節點指針,節省了空間。
候選着法優化
Playout過程中可以只生成一次所有着法,之後每步只需
旋轉根
第一次收到getPoint指令前程序需要完整地構建樹,但之後收到getPoint後可以根據雙方選擇的着法把根變換到原來根節點的某個孫子節點,這樣可以繼承之前回合搜索的結果。
動態分配內存開銷會比較大,我實現了一個內存池,用雙鏈表儲存尚未分配的節點。節點的兩個信息score及visited剛好可以用作雙鏈表的兩個指針,節省空間。
實現該方法後需要實現子樹的析構操作,比較耗時。測試發現這樣做得不償失,因此沒有採用。
MCTS Solver
實驗效果不理想,原因可能是selection和backpropation過程中更新game-theoreticvalue的代價太大了, 導致迭代次數大幅下降。
並行
主要有兩類並行模式:Leaf parallelisation和root parallelisation,前者是並行執行多個playout操作,後者是並行計算多棵搜索樹。實現中採用了前者,用OpenMP實現了簡單的並行模式。
對局結束後需要釋放樹佔用的資源,程序中實現一個singleton對象,該對象的析構函數會釋放樹佔用的資源。
如果允許使用多線程,請在Visual
Studio配置屬性的C/C++選項卡的語言選項裏添加“OpenMP支持“,並修改MCTS.cc開頭的#define NTHREAD 1,修改爲#define NTHREAD 3,或系統可用線程數。