任務
實現支持INSERT INTO DB VALUES(...)和SELECT a, b, c FROM x, y WHERE a=b AND b<100 AND c='a'的SQL引擎。
系統架構
程序的架構如下:
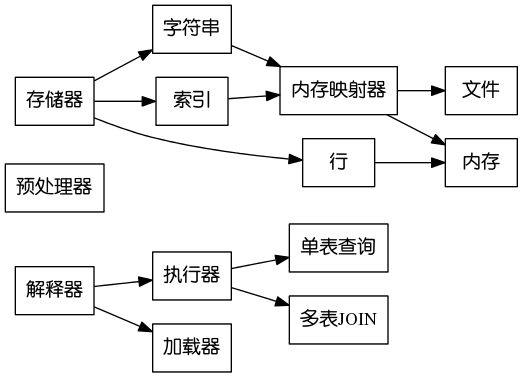
存儲模型
行數據
所有記錄中的integer類型及varchar類型字符串的hash儲存在行(類型爲Record,即int*的別名)中,每個表用一個vector<Row>記錄它的所有行。使用int*而不是單獨的類表示行的原因是節省內存以及減少複雜性。
字符串
注意到varchar的大小通常很大,故不把字符串與integer行數據存儲在一起,而是用單獨的數據結構保存。程序中使用了一個內存映射器(見下文)存儲字符串。
索引
使用內存映射器存儲。
內存映射器
內存映射器MemoryMap負責分配內存以及把文件抽象爲虛擬內存。MemoryMap有一個容量值,代表當前加載的所有數據的大小之和。因爲它使用malloc分配內存,內存的精確計算比較複雜,所以實現中假設malloc再分配所需內存外的額外開銷是16字節。
當需要分配更多內存或者試圖獲取的頁未被加載時(即產生了page
fault),內存映射器使用LRU的緩存策略,把最近使用時刻最久的節點卸載,反覆執行卸載操作直到有足夠的內存加載新數據。卸載時會確定該數據是否爲髒頁,如果爲是則保存到文件中。
索引結構
程序中實現了Size-balanced tree和B+ tree兩種索引結構。當索引可以完整放在內存中時使用前者,否則就使用B+ tree。
Size-balanced tree
根據子樹大小實現平衡的binary search tree,屬於一類weight-balanced
tree,網上盛傳由陳啓峯發明,但我曾發現更早時可能即有出處,但陳啓峯當初的Pascal程序影響深遠,尤其是他的maintain函數寫法。選用這個樹結構的原因是它不會引入額外的satellite
data (比如red-black tree的顏色、AVL
tree的平衡信息等),節省內存佔用,對於節點較小時4字節的差異可能對性能有不小的影響。
B+ tree
MemoryMap是管理虛擬內存的類,調用者可以向它申請分配一段內存或者要求訪問指定虛擬內存地址處的頁。MemoryMap使用LRU緩存調用者訪問的頁,當請求的頁過多時會把髒頁寫入文件並從內存中卸載該頁。MemoryMap中的_head雙鏈表管理內存中加載的頁,新訪問的頁會被插入到鏈表頭。需要卸載頁時就從鏈表末尾取出頁。
Cache策略
實現了Least recently
used緩存算法,它被內存映射器使用。MemoryMap中的_head爲雙向循環鏈表,鏈表中的元素按照最近使用時刻從小到大順序從前到後排列。當內存映射器加載新數據時,把對應的節點移動到鏈表頭部。
寫策略使用write-back,即當該cache line即將被替換時寫入支撐文件。
考慮過使用adapative replacement cache、multi-queue等高級的緩存策略,但考慮到單次操作的開銷可能比較大,沒有採用。
查詢執行策略
由執行器處理查詢。
單表查詢
單表查詢時,執行器選取該表限制最緊的列(即滿足該列條件的記錄數最少),使用Size-balanced tree或B+ tree的range query操作從索引中取出所有滿足條件的記錄,然後濾去在其他列上不滿足條件的記錄。
多表JOIN
對於select操作涉及的每個表,考察只考慮關於這個表,有多少條記錄滿足查詢要求,記這個值爲
之後每次迭代選取一個表加入到生成樹中,每一輪迭代選取的表
對於
中的每條記錄,從 的索引中查找等值的記錄,從 與 的笛卡爾積中選擇這些滿足條件的記錄作爲新的 和 兩個有序表做合併操作 對於
條件,把 的所有記錄,以 爲關鍵字組織爲散列表。對於 的每條記錄,在散列表裏查找鍵值爲 的記錄。 這裏使用的自己寫的散列表,用了一個小技巧使散列表的清空操作時間複雜度爲 。
遇到的問題
gcc 4.6.1處理模板類構造函數時的bug
類模板A的構造函數裏如果引用了之前定義的某個全局類實例的方法,A的多個實例只會調用該方法一次。本地測試發現gcc 4.7.3不存在該問題。
Runtime Error
遇到了一些數組下標越界的segfault,比如memcpy越界。
內存用溢後的segfault往往之後纔會顯現出來,比如在之後的某次free(可能是在clear某個vector時)segfault,
使用valgrind結合gdb,把這些問題都找出來了。
另外因爲內存佔用難以估算,我把很多數據結構都從可能使用malloc的STL容器換成自制的使用靜態存儲空間的類。
其他
網站調用外部命令
tar xf filename解壓文件,當文件名爲-時tar會讀取stdin而產生Invalid Submission。服務器使用
make -C client編譯選手代碼,容易執行不可預料命令評測系統是將選手代碼和評測代碼鏈接在一起的,評測系統
new的字符串等對象會影響到堆中對象存儲,導致program break增大, 會影響到resident set size佔用。以後開課時內存限制我覺得把load等方法的參數改成const char *[]比較好,並聲明它使用的是靜態存儲空間.bss或.data段,從而不會在運行時產生不可預知的內存佔用,使選手對內存佔用的估計更加準確。不知道服務器的內存有多少,但是選手可以通過把文件儲存在
/dev/shm/下,這個目錄在很多Linux發行版裏默認掛載爲tmpfs文件系統,並且權限爲1777, 讀寫它有近似於訪問內存的性能。選手代碼如果把臨時文件存儲到裏面會有巨大的性能提升,甚至可以完全勝過算法上帶來的提升。新開的服務器
http://166.111.71.204:18080/course/index.jsp,從提交結果上來看,感覺應該沒有安裝g++-multilib,所以不支持-m32命令行選項,無法產生32位ELF可執行文件。
遺憾是期間有很多考試,沒有足夠的時間做大作業,離完善還差很遠。我的JOIN性能較低,記錄換用列儲存模式後可能會快一些。最後達到這一令人滿意的分數後也有一些壓力,不敢繼續優化了,因爲會影響到他人。比如並行的代碼沒有添加,也沒有嘗試其他的緩存算法。最初設想過使用OpenMP加速,但是LRU使用的雙鏈表以及B+
tree使用的節點可能從磁盤讀,並發的話感覺會產生很多衝突,可能還要換上lock-free數據結構。B+
tree的節點數也沒調整過,沒有對磁盤讀寫性能做調整,比如考慮磁盤的/sys/class/block/sda/queue/minimum_io_size等,以及使用open(2)的O_DIRECT進行直接IO。JOIN算法的框架還是生成樹,還沒有對錶的限製做進一步的分析。B+
tree和Size-balanced
tree外也沒有考慮過其他的數據結構。表信息存儲也沒考慮到其他方式,比如當字符串較小時和行數據內聯從而減少潛在的page
faults數目以及提升緩存命中率,
可能帶來性能提升。另外代碼沒有採用嚴謹的軟件工程式寫法,因爲對於這樣的Online
Judge形式測評網站,增大耦合度、減少文件數目而不去理會可複用性對性能的提升和開發時間的減少都有好處。所以這裏也算是一個遺憾吧,如果換成嚴謹的寫法,花的時間應該會乘以2,可能還不止。
課程建議
增設程序實現類的作業。
一次提交的週期太長了,特別是要考慮後幾個測試點時,通常要一個小時以上的等候時間。而網站是順序評測的,一個測試點不通過就不予以評測之後的,同學要花費很大的精力等待。即使寫出來了但因爲調試的困難性,可能還是要和網站交互很多次,影響效率。如果服務器內存大的話可以把加載的數據放到
/dev/shm/裏,提示選手可以把臨時文件寫進去,但要注意容量不要超額,mount -o remount,size=4000M /dev/shm類似這樣修改這個目錄的大小限制。本質上選手還是在讀寫文件,但能大幅減少等待時間。Course Project for Database System網站提供具體的編譯錯誤信息。
Group ID使用版本號排序而非字典序……
大作業說明文檔中闡述服務器端程序的構建方式(選手程序如何鏈接,使用的gcc、glibc版本,編譯選項等)
明確進程限制的各項參數含義:如內存是指maximum resident set size(
setrlimit的資源號RLIMIT_RSS)還是其他的,或者ulimit -m,後者的話本質上還是setrlimit,但是隻修改了soft limit,選手程序可以調用setrlimit輕易繞過。應該同時指定-H修改hard limit,hard limit非特權用戶是不能提升的。服務器用的Ubuntu 8.04比較舊了,漏洞很多,包括很多local root exploit。
參考資料
Handbook of Data Structures and Applications
The Multi-Queue Replacement Algorithm for Secon Level Buffer Caches
助教同學是我三年大學生涯碰到的最好的助教了,1月2日大家都還沒動時還打電話通知,以及碰到的各種問題都會很快回覆。還會給我們發程序的coredump,耐心解釋評測系統(比如我詢問是不是用setrlimit(RLIMIT_RSS, ...)做內存限制的,都很快答覆了。程序的Runtime
Error也會來通知我們……