LLVM's C++ API doesn't offer a stability guarantee. This means
function signatures can change or be removed between versions, forcing
projects to adapt.
On the other hand, LLVM has an extensive API surface. When a library
like llvm/lib/Y relies functionality from another library,
the API is often exported in header files under
llvm/include/llvm/X/, even if it is not intended to be
user-facing.
To be compatible with multiple LLVM versions, many projects rely on
#if directives based on the LLVM_VERSION_MAJOR
macro. This post explores the specific techniques used by ccls to ensure
compatibility with LLVM versions 7 to 19. For the latest release (ccls
0.20241108), support for LLVM versions 7 to 9 has been
discontinued.
Given the tight coupling between LLVM and Clang, the
LLVM_VERSION_MAJOR macro can be used for both version
detection. There's no need to check
CLANG_VERSION_MAJOR.
After migrating from
Vim to Emacs as my primary C++ editor in 2015, I switched from Vim
to Neovim for miscellaneous non-C++ tasks as it is more convenient in a
terminal. Customizing the editor with a language you are comfortable
with is important. I found myself increasingly drawn to Neovim's
terminal-based simplicity for various tasks. Recently, I've refined my
Neovim setup to the point where I can confidently migrate my entire C++
workflow away from Emacs.
This post explores the key improvements I've made to achieve this
transition. My focus is on code navigation.
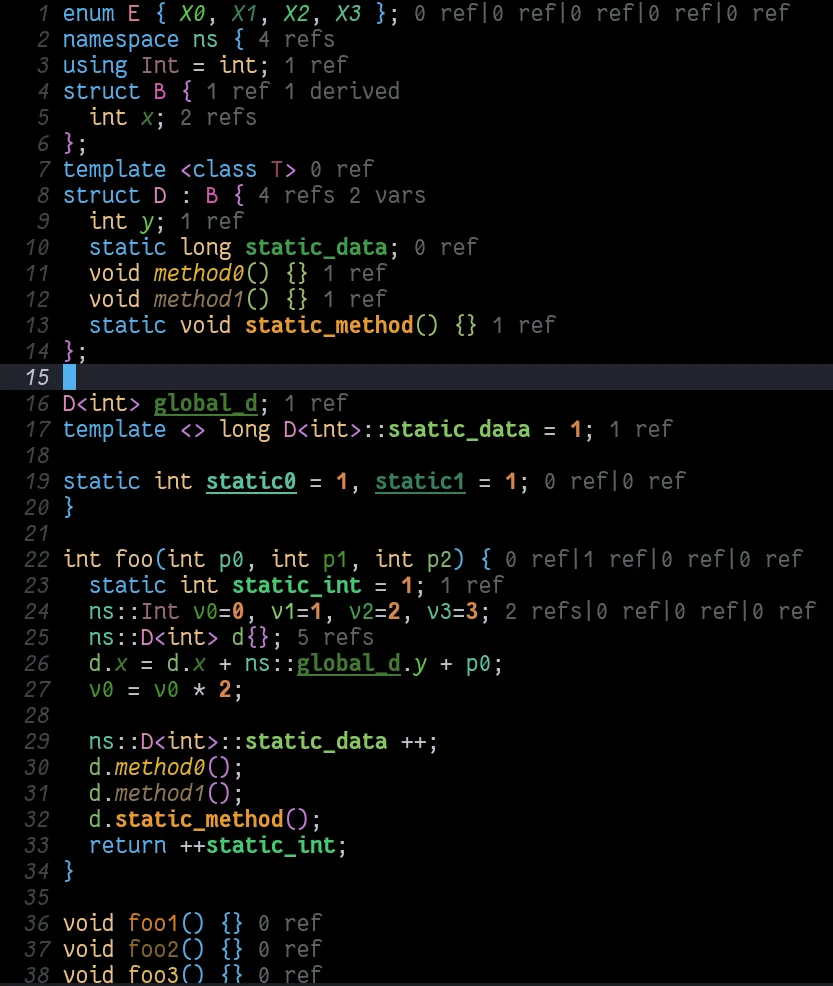
I've spent countless hours writing and reading C++ code. For many
years, Emacs has been my primary editor, and I leverage ccls' (my C++ language
server) rainbow semantic highlighting feature.
The feature relies on two custom notification messages
$ccls/publishSemanticHighlight and
$ccls/publishSkippedRanges.
$ccls/publishSemanticHighlight provides a list of symbols,
each with kind information (function, type, or variable) of itself and
its semantic parent (e.g. a member function's parent is a class),
storage duration, and a list of ranges.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
structCclsSemanticHighlightSymbol { int id = 0; SymbolKind parentKind; SymbolKind kind; uint8_t storage; std::vector<std::pair<int, int>> ranges;
std::vector<lsRange> lsRanges; // Only used by vscode-ccls };
An editor can use consistent colors to highlight different
occurrences of a symbol. Different colors can be assigned to different
symbols.
Tobias Pisani created emacs-cquery (the predecessor to emacs-ccls) in
Nov 2017. Despite not being a fan of Emacs Lisp, I added the rainbow
semantic highlighting feature for my own use in early 2018. My setup
also relied heavily on these two settings:
Bolding and underlining variables of static duration storage
Key symbol properties (member, static) were visually prominent in my
Emacs environment.
My Emacs hacking days are a distant memory – beyond basic
configuration tweaks, I haven't touched elisp code since 2018. As my
Elisp skills faded, I increasingly turned to Neovim for various editing
tasks. Naturally, I wanted to migrate my C++ development workflow to
Neovim as well. However, a major hurdle emerged: Neovim lacked the
beloved rainbow highlighting I enjoyed in Emacs.
Thankfully, Neovim supports "semantic tokens" from LSP 3.16, a
standardized approach adopted by many editors.
I've made changes to ccls (available on a
branch; PR)
to support semantic tokens. This involves adapting the
$ccls/publishSemanticHighlight code to additionally support
textDocument/semanticTokens/full and
textDocument/semanticTokens/range.
I utilize a few token modifiers (static,
classScope, functionScope,
namespaceScope) for highlighting:
1 2 3 4 5
vim.cmd([[ hi @lsp.mod.classScope.cpp gui=italic hi @lsp.mod.static.cpp gui=bold hi @lsp.typemod.variable.namespaceScope.cpp gui=bold,underline ]])
treesitter, tokyonight-moon
While this approach is a significant improvement over relying solely
on nvim-treesitter, I'm still eager to implement rainbow semantic
tokens. Although LSP semantic tokens don't directly distinguish symbols,
we can create custom modifiers to achieve similar results.
In the user-provided initialization options, I set
highlight.rainbow to 10.
ccls assigns the same modifier ID to tokens belonging to the same
symbol, aiming for unique IDs for different symbols. While we only have
a few predefined IDs (each linked to a specific color), there's a slight
possibility of collisions. However, this is uncommon and generally
acceptable.
For a token with type variable, Neovim's built-in LSP
plugin assigns a highlight group
@lsp.typemod.variable.id$i.cpp where $i is an
integer between 0 and 9. This allows us to customize a unique foreground
color for each modifier ID.
local func_colors = { '#e5b124', '#927754', '#eb992c', '#e2bf8f', '#d67c17', '#88651e', '#e4b953', '#a36526', '#b28927', '#d69855', } local type_colors = { '#e1afc3', '#d533bb', '#9b677f', '#e350b6', '#a04360', '#dd82bc', '#de3864', '#ad3f87', '#dd7a90', '#e0438a', } local param_colors = { '#e5b124', '#927754', '#eb992c', '#e2bf8f', '#d67c17', '#88651e', '#e4b953', '#a36526', '#b28927', '#d69855', } local var_colors = { '#429921', '#58c1a4', '#5ec648', '#36815b', '#83c65d', '#419b2f', '#43cc71', '#7eb769', '#58bf89', '#3e9f4a', } local all_colors = { class = type_colors, constructor = func_colors, enum = type_colors, enumMember = var_colors, field = var_colors, ['function'] = func_colors, method = func_colors, parameter = param_colors, struct = type_colors, typeAlias = type_colors, typeParameter = type_colors, variable = var_colors } fortype, colors inpairs(all_colors) do for i = 1,#colors do for _, lang inpairs({'c', 'cpp'}) do vim.api.nvim_set_hl(0, string.format('@lsp.typemod.%s.id%s.%s', type, i-1, lang), {fg=colors[i]}) end end end
vim.cmd([[ hi @lsp.mod.classScope.cpp gui=italic hi @lsp.mod.static.cpp gui=bold hi @lsp.typemod.variable.namespaceScope.cpp gui=bold,underline ]])
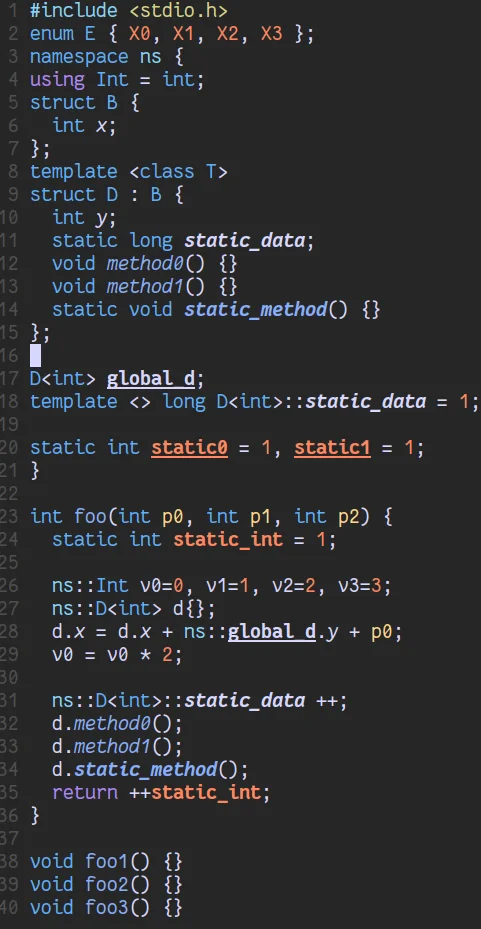
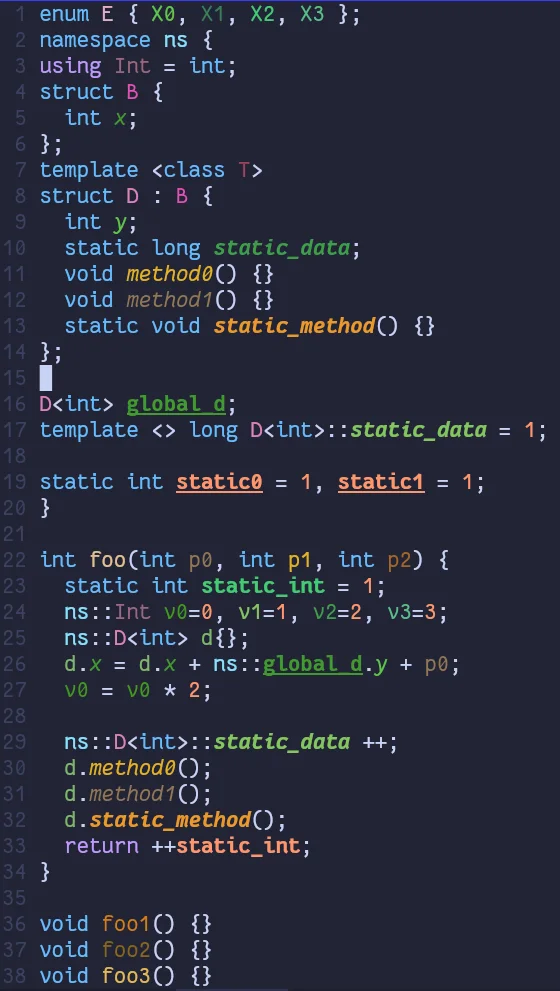
Now, let's analyze the C++ code above using this configuration.
tokyonight-moon
While the results are visually pleasing, I need help implementing
code lens functionality.
Inactive code highlighting
Inactive code regions (skipped ranges in Clang) are typically
displayed in grey. While this can be helpful for identifying unused
code, it can sometimes hinder understanding the details. I simply
disabled the inactive code feature.
1 2 3 4 5
#ifdef X ... // colorful #else ... // normal instead of grey #endif
Refresh
When opening a large project, the initial indexing or cache loading
process can be time-consuming, often leading to empty lists of semantic
tokens for the initially opened files. While ccls prioritizes indexing
these files, it's unclear how to notify the client to refresh the files.
The existing workspace/semanticTokens/refresh request,
unfortunately, doesn't accept text document parameters.
In contrast, with $ccls/publishSemanticHighlight, ccls
proactively sends the notification after an index update (see
main_OnIndexed).
// Update indexed content, skipped ranges, and semantic highlighting. if (update->files_def_update) { auto &def_u = *update->files_def_update; if (WorkingFile *wfile = wfiles->getFile(def_u.first.path)) { wfile->setIndexContent(g_config->index.onChange ? wfile->buffer_content : def_u.second); QueryFile &file = db->files[update->file_id]; // Publish notifications to the file. emitSkippedRanges(wfile, file); emitSemanticHighlight(db, wfile, file); // But how do we send a workspace/semanticTokens/refresh request????? } } }
While the semantic token request supports partial results in the
specification, Neovim lacks this implementation. Even if it were, I
believe a notification message with a text document parameter would be a
more efficient and direct approach.
1 2 3 4 5 6 7
exportinterfaceSemanticTokensParamsextendsWorkDoneProgressParams, PartialResultParams { /** * The text document. */ textDocument: TextDocumentIdentifier; }
We require assistance to eliminate the
$ccls/publishSemanticHighlight feature and adopt built-in
semantic tokens support. Due to the lack of active maintenance for
vscode-ccls, I'm unable to maintain this plugin for an editor I don't
frequently use.
Misc
I use a trick to switch ccls builds without changing editor
configurations.
In object files, certain code patterns embed data within instructions
or transitions occur between instruction sets. This can create hurdles
for disassemblers, which might misinterpret data as code, resulting in
inaccurate output. Furthermore, code written for one instruction set
could be incorrectly disassembled as another. To address these issues,
some architectures (Arm, C-SKY, NDS32, RISC-V, etc) define mapping
symbols to explicitly denote state transition. Let's explore this
concept using an AArch32 code example:
Within the LLVM project, MC is a library responsible for handling
assembly, disassembly, and object file formats. Intro
to the LLVM MC Project, which was written back in 2010, remains a
good source to understand the high-level structures.
In the latest release cycle, substantial effort has been dedicated to
refining MC's internal representation for improved performance and
readability. These changes have decreased compile
time significantly. This blog post will delve into the details,
providing insights into the specific changes.
GNU ld's output section layout is determined by a linker script,
which can be either internal (default) or external (specified with
-T or -dT). Within the linker script,
SECTIONS commands define how input sections are mapped into
output sections.
Input sections not explicitly placed by SECTIONS
commands are termed "orphan
sections".
Orphan sections are sections present in the input files which are not
explicitly placed into the output file by the linker script. The linker
will still copy these sections into the output file by either finding,
or creating a suitable output section in which to place the orphaned
input section.
GNU ld's default behavior is to create output sections to hold these
orphan sections and insert these output sections into appropriate
places.
Orphan section placement is crucial because GNU ld's built-in linker
scripts, while understanding common sections like
.text/.rodata/.data, are unaware
of custom sections. These custom sections should still be included in
the final output file.
Grouping: Orphan input sections are grouped into orphan output
sections that share the same name.
Placement: These grouped orphan output sections are then inserted
into the output sections defined in the linker script. They are placed
near similar sections to minimize the number of PT_LOAD
segments needed.
The ELF object file format is adopted by many UNIX-like operating
systems. While I've previously delved
into the control structures of ELF and its predecessors, tracing the
historical evolution of ELF and its relationship with the System V ABI
can be interesting in itself.
The format consists of the generic specification, processor-specific
specifications, and OS-specific specifications. Three key documents
often surface when searching for the generic specification:
The TIS specification breaks ELF into the generic specification, a
processor-specific specification (x86), and an OS-specific specification
(System V Release 4). However, it has not been updated since 1995. The
Solaris guide, though well-written, includes Solaris-specific extensions
not applicable to Linux and *BSD. This leaves us primarily with the
System V ABI hosted on www.sco.com, which dedicates Chapters 4 and 5 to
the ELF format.
Let's trace the ELF history to understand its relationship with the
System V ABI.