青蛙过河
任务
实现青蛙过河的小游戏。为了增加趣味性,对作业任务有所扩展,场景上布置了两个堡垒发射子弹,青蛙需要躲避三类子弹(一类是跟踪弹,一类是正弦波子弹)、经木板穿过河流到达右下角(场景开始时会有箭头标志指示终点的位置)。之后游戏会变难,即堡垒生产子弹的速度加快,新产生子弹的速度也会变快。
使用说明
依赖
- gtkmm
- cairomm
构建
程式依赖 gtkmm,兼容 2 和 3 两类版本,在 gtkmm-3.4.0 及 gtkmm-2.24.2 上构建通过。
使用命令
1 | ./configure --prefix=/tmp/ins |
生成依赖 gtkmm-3 的程式 /tmp/ins/bin/frog-river。
使用命令
1 | ./configure --prefix=/tmp/ins --with-gtkmm2 |
生成依赖 gtkmm-2 的程式 /tmp/ins/bin/frog-river。
autotools 生成的 Makefile 为 GNU Make 格式,如果是 FreeBSD、SunOS 之类的系统需要使用 gmake 代替 make。
程式运行时使用到的图片位于 $(pkgdatadir)/img ,所以要
make install 后才能正常执行程式。
本报告位于 report/report.pdf ,可以用
make -C report report.pdf 根据
report/report.org 生成。
运行
程式的可定制性非常强,提供了丰富的命令行选项用以控制运行时行为,帮助中提供了一些有趣的用例,
比如修改河流宽度、位置,如果 river-y 超过 100
就会从场景上消失。下面有几个用例让河流消失来产生更好的效果。 又如
-f
可以指定堡垒位置,结合其他三类子弹就可以实现各类奇异效果,比如弹幕游戏,写字等等。
可以试试看:
1 | FrogRiver 0.1 |
演示
data/demo.avi是示例视频。



程式设计
下面逐一介绍各个类别的作用:
Core
存放公共的实用函数以及程式需要用到的简单几何库,描述点、线段,可以处理 线段与多边形的相交。
Config
有一个实例 cfg,记录虚拟画布大小、河流位置大小、青蛙大小、青蛙移动速度 等,下面诸类别大多都用了这个物件的资料。使用 gengetopt 生成 Cmdline.h 用于命令行选项的解析。
Frog
Frog 类别继承自 Point,提供了 move 方法相应键盘事件,以及 draw 方法用于 在Cairo::Context 上绘出青蛙的图像。以下诸类别很多都有这个 draw 方法。
Board
表示木板类别,该类别处理碰撞、移动事件。移动时会考虑青蛙是否搭载在上面, 是则把青蛙也一并移动了。碰撞为弹性碰撞,动能不损耗。提供方法用于计算和 另一块木板的相撞时刻。
BoardLine
Board 的聚合(aggregate)。提供 init 静态方法生成初始场景的木板,位置、长度都是随机的,但质量相同。
BoardLine 记录的是某一时刻某行的木板状态, 当用 advanceTo 方法要求把时刻移动至将来的另一个时刻时, 它会枚举两个时刻间发生的所有碰撞事件并一一处理。
Bullet
Bullet 类别表示的是方向固定的点状子弹,有 inCanvas 方法用于判断是否还在场景上, 以及 advance 方法表示移动一段时间,报告是否击中了青蛙。击中的判断方式为算是 开始时刻和目标时刻子弹的运动轨迹(线段),判断是否和青蛙的 hitbox 相交。 为了使用 heterogenuous 列表实现多型,Bullet 中一些方法用了虚函数。
TracerBullet 类别代表一种跟踪弹,继承自 Bullet,覆盖了 advance,移动方式变为 速度方向始终指向青蛙的当前位置。inCanvas 方法则变为超过一定时限则判定追踪弹消失。
Fort
表示堡垒,会源源不断地射出子弹,给青蛙的移动造成困扰。它和 Bullet 的关 系就像是 Board 和 BoardLine 的关系,同样也是记录当前描述状态(包含时刻), 呼叫 advanceTo 方法时则转发给 heterogenuous 的 Bullet 列表。如果离赏赐 发射子弹的事件超过了某一阈值则产生出一颗新子弹。对于不同的子弹,可以用 工厂函数,但我觉得在这里用有杀鸡用牛刀的感觉,因而未予使用。
FrogRiver
将之前的物件聚合起来搭成的场景,继承自
Gtk::DrawingArea,程式逻辑等都在 这个物件里判断。根据
cfg.updateinterval 设置触发 ondraw 用于重绘场景
的间隔。触发 ondraw
事件后,依次绘制河流、木板、堡垒、子弹、青蛙。其中
绘制木板时会涉及到碰撞模拟,河流上不同行的木板间是不会相互干扰的,所以
可以由不同的线程处理不同的行,工作线程间不会有通信。线程
Main.cc
最后在 Main.cc 中展示出界面。
心得体会
这次作业是对 pthreads 的实践机会,但更多的是培养了写 gui 程式的能力。写 程式的过程中深深体会到 C++ 的样本(boilerplate)代码太多,表现能力有限, 以及感受到物件导向程式设计的种种限制。
比如 Fort 中我本来打算用工厂函数产生各种类型子弹(当然现在子弹型别不是很 多,没有必要这样写),工厂函数绕不过去的原因和 C++ 是 static 加 nominative typing system 有很大关系,无法方便地使用 heterogenuous 列表, 而要用指针或引用以基类比表示多个类别的共同联系。如果在 Ruby 这类 duck typing system 离就可方便地储存 heterogenuous 列表,OCaml 这类 structural typing system 中也可以,或者用包含函数的 algebraic data type 或着相应的existential data type 表示,这样产生的样本代码 (boilerplate) 就更少了。一种类型不安全的解决方式有用一个标志用于表示子 弹型别,另用一个 void* 的数据供强制类型转化为相应型别。
Config 单独提取出来提供了很大的灵活行,本来每个类维护自己的
static const
变量表示配置也是可以的,但不利于集中式管理。如果项目复杂 Config
可能还得展现层次化的结构。其实说到集中式我就联想起 git,以及和它的模式
对应的 subversion,这个有点扯远了,但可以看出来概念之间的融会贯通相当重
要。
物件导向程式设计时门博大精深的艺术。撇开型别的选取与设计,假设型别间的 认识关系确定了,那么问题可以部分看为添加一些有向边满足型别之间的认识关 系。而那些千变万化的设计模式,不少是以增加新类来达到的,可愿意部分看作 一个 minimum Steiner tree 问题,如果让型别联系起来。设计模式往往强调减 小耦合,又可以部分看作是minimum spanning tree with restricted degrees。 这些是我对物件导向程式设计的窥豹一斑,可惜未能见全貌。
程式原始码
位于 src/ 目录。
Mandelbrot set
任务
实现三种并行的Mandelbrot set实现,分别使用MPI、OpenMP和Pthreads。

使用说明
构建
程式采用 autotools 管理,./configure提供了大量选项,
除了产生 MPI/OpenMP/Pthreads 三种并行库的程式外,
还有其他用于性能调优的选项。程式有如下选项:
MPI
生成使用 MPI 库的版本。
1 | ./configure --with-mpi |
OpenMP
生成使用 OpenMP 的版本。
1 | ./configure --with-openmp |
Pthreads
生成使用 Pthreads 的版本。
1 | ./configure --with-pthread |
无输出模式
选项 --without-output
,用于提示程式不要产生输出,将无法产生 PGM 或是显示图片,
该选项用于基准测试时使用,性能会有少许提升。
float
复数计算时使用 float 而非 double,性能会有少许提升。
SSE2
选项 --without-sse2
,同时计算两个点,性能有大幅提升。
下面是和 MPI 配合使用的例子:
1 | ./configure --with-sse2 --with-mpi |
命令行选项
1 | src/mandelbrot -h Mandelbrot 0.1 |
图形使用者介面设计
输出模式 -o x 提供了如下键绑定:
u: scale top-left by ratio 2 j: scale bottom-left by ratio 2 k: scale bottom-right by ratio 2 i: scale top-right by ratio 2 Space: scale center by ratio 1/2 Enter: restore to original range Button1 click: scale pointer center by ratio 4 Button3 click: scale pointer center by ratio 1/4 Button1 drag: scale up by (width/regionwidth, height/regionheight) Button3 drag: scale down by (regionwidth/width, regionheight/height)
Button1 单击放大,Button3 单击缩小。 Button1 拖曳放大查看指定区域,Button3 拖曳按比例缩小指定区域。 Enter 换原到命令行选项指定区域。
程式设计
为了可以使用 MPI+Pthreads 或者 MPI+OpenMP,程序分为三个层级,执行续层建立在串行层之上,程序层建立在执行续层之上,类似 TCP/IP 协议栈,
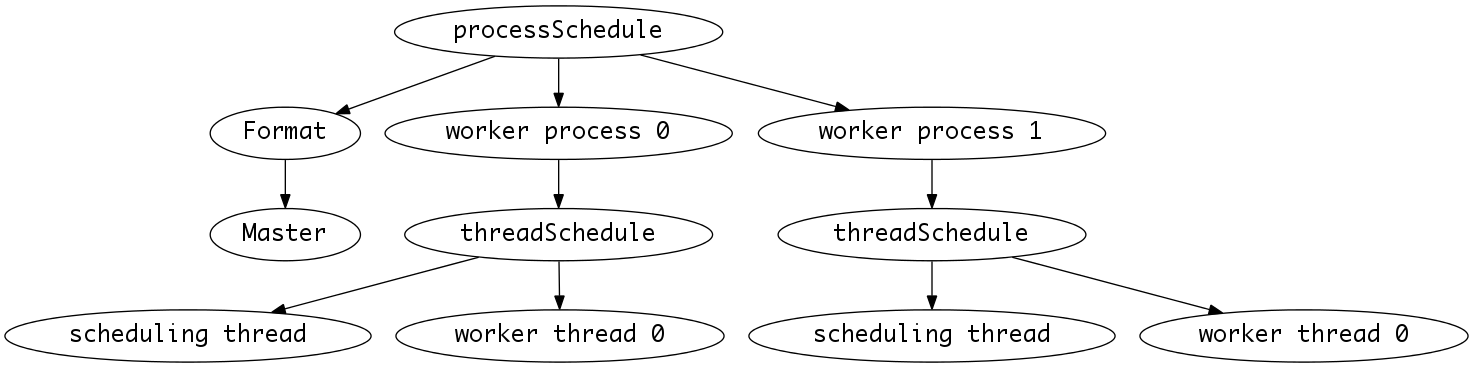
Core
串行层。包含主要计算模块和 SSE2 优化过的版本。
实现了一个名唤 Callable<T,R>
的函数对象,相当于函数
还描述了 Task 这一数据类型,表示任务的座标范围、解析度,同时提供了计算成的点的储存位置,以及一个行通知器, 任务的执行者计算完一行后会通过这个通知器告知呼叫者。
比如1程序数时1执行绪时,任务从processSchedule转交给threadSchedule再转交给mandelbrot,它计算完一行后通过这个回调函数执行XPutImage往屏幕上绘制一行。 当执行绪数大于1时,任务从processSchedule转交给threadSchedule后,threadSchedule会给这个回调函数包装一个mutex成为MutexCallable, 防止回调函数同时被多个执行续执行产生错误。 当程序数大于1时,实际计算任务不是由主程序执行的,而 X 窗口是由主程序打开的,所以这些程序不能往屏幕上绘制一行,此时的回调函数是空的。
ThreadSchedule
执行续层。OpenMP 和 Pthreads 的实现在这里,建立在 Core 中串行实现 mandelbrot 函数之上,提供了多执行绪的调度。 采用 thread pool 模式,由主执行绪实施任务的调度。
Channel
被 ThreadSchedule 依赖用于实现不同执行续间的通信,Channel 是一个执行续安全的队列,主执行续往里面塞任务, 工作执行续从中读取任务进行处理。
ProcessSchedule
程序层。MPI 的实现在这里,建立在 ThreadSchedule 之上,提供了多程序的调度。实现和 ThreadSchedule 非常像, 也是采用 producer/consumer 模型,由主程序进行任务的调度,采取自定义的协议进行通信。
Master
Format 类型的一个成员,负责主程序的调度。如果未启用 MPI,那么 Master::run 只是简单地把任务转交给 ThreadSchedule, 否则就指派任务给个工作程序并收集工作程序生成的资料。这个模块的出现源于我需要让用户能和 Xlib 窗口交互, MPI 的工作程序不能立刻结束,所以单独写了这个 Master 类别负责 把任务指派给工作程序。
Format
表示输出的各种后端,类似 Gnuplot 中的 terminal,输出的数据来自迭代时的 escape count。 采用 XFormat 输出时,会显示颜色,颜色是根据 HSV 颜色模型中饱和度0.6,亮度1,色相根据 escape count 选取而来。
这里的 Format 的任务不只是产生输出而已,它也涉及数据的产生。 因为不同的输出往往需要不同的数据处理方式,Core 中的 mandelbrot 函数会把数值写到一个数组里去,写完一行后还会通过一个回调函数 告知已经处理完一行。这里这个数组就是由 Format 提供的,比如对于 PGM 图片格式,提供的数组就是一个大小为 width * height 的数组, 而对于 Xlib 图形显示,数组是 XImage 中的 data。
这里具体讲 Format 的一个子类型 XFormat,XFormat 物件会做一些 Xlib 的初始化工作产生一个图形界面,生成一个位图数组供 mandelbrot 函数写入。 当某个 ThreadSchedule 管理的执行续执行的 mandelbrot 计算完一行后,通过回调函数(Callable<int> Task.notifier)告知呼叫者,呼叫者会考虑当前是否工作在 MPI 多程序模式下, 如果不是那么就用 XPutImage 显示出这一行。如果使用了 Pthreads,threadSchedule 会包装 Callable<int> 产生执行续安全的 MutexCallable<int> 作为回调函数。
其实 Task.data 字段也可以替换成回调函数以提供更大的灵活性,但我为了性能考虑还是决定使用数组,而一行执行一次回调函数的开销还是可以忍受的。
这里由 Format 管理 Master 的意图是 Xlib
图形界面在初次显示后还会有放大、缩小的需求,工作程序不能产生完第一幅位图后就退出,
需要继续等待主程序的调度,为了统一接口,干脆让 Format 内置一个 Master
fsm 字段,对于一次性输出的 Format 比如 PGM,PGM::render 做的事就是 先用
fsm.run(tk) 产生数据再输出,而 XFormat
则会等待用户指令。
另外有一个 TimeFormat,继承自 NullFormat,会调用 gettimeofday 显示主程序的运行时间。
分析
设串行程序的计算量为
OpenMP 版本
令
每个执行续的工作量为
总共
Pthreads 版本
令
共有
每个工作执行续的计算量平均为
总共
MPI 版本
令
主程序用广播通知各程序座标解析度等信息,这一过程可以用 binomial tree 等方式优化至
,通信量为 。 平均每个工作程序分得
的计算任务,通信量为 ,而主程序的通信量为 。 每个工作程序要把结果传给主程序,通信量
,主程序的通信量 。 主程序用广播通知各程序退出,通信量应为
。 总共
。 基准测试
以下所有测试中y座标解析度 --yr 的值都统一为了
10000,最大escape count都为255。
MPI
我测试了三种版本,除了普通版本外,还有一种是用float替换double,另一种是用
SSE2 指令同时处理两个 double。 三个版本的构建方式有略微区别,后面会给出
configure 时的选项。但它们的运行方式都是
1 | mpirun -n ? src/mandelbrot -o time --xr ? --yr 10000 |
其中问号处分别填写程序数、x坐标解析度、y坐标解析度。主程序会输出计算部分的执行时间。程式运行在 FIT 集群上。
--without-output CXXFLAGS=-O3 --with-mpi
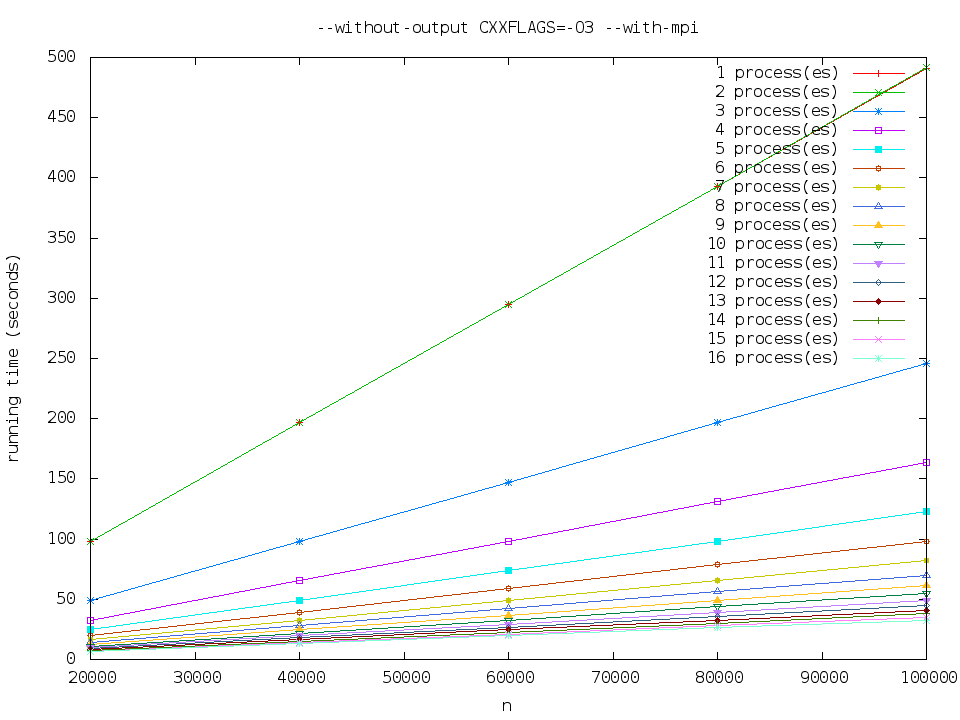
可以观察到执行时间大致是关于x座标解析度的一次函数,和时间复杂度相吻合。
注意到1程序数和2程序数的执行时间没有太大区别。这是因为
--without-output CXXFLAGS=-O3 --with-mpi --with-float
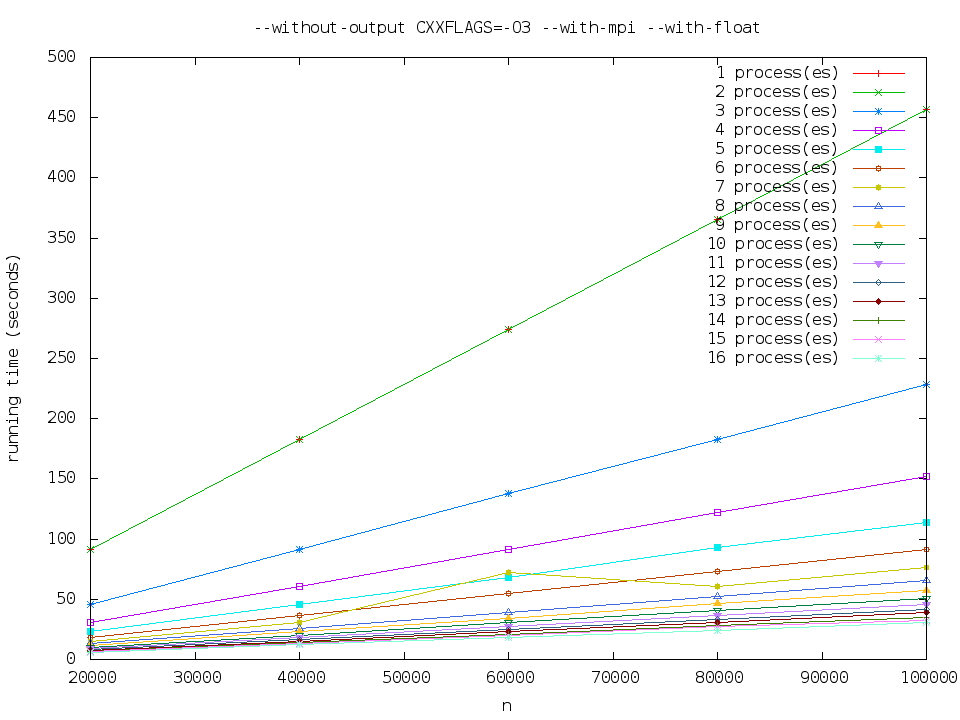
执行时间比 mpi-normal 略少。
--without-output CXXFLAGS=-O3 --with-mpi --with-sse2
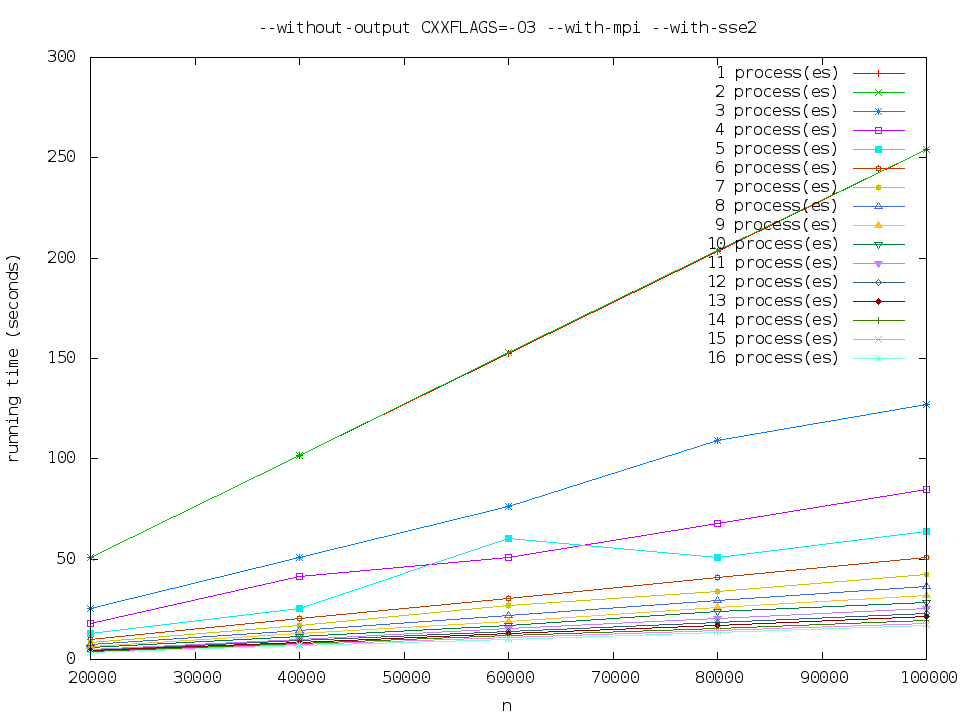
执行时间大致是 mpi-normal 的一半。
极限测资
我还对96、112、128程序数,
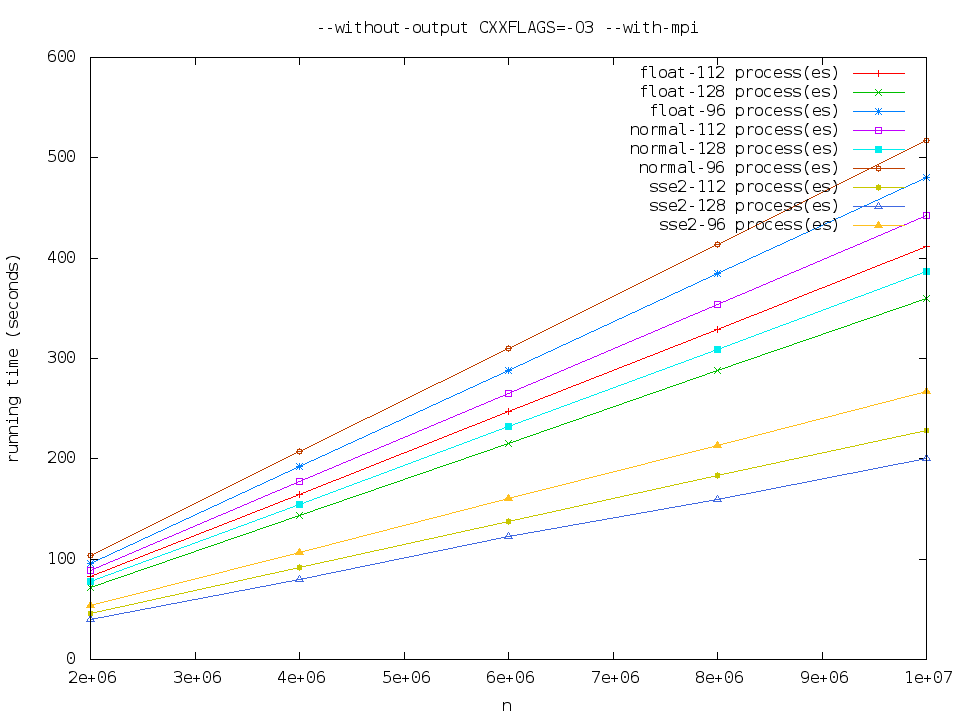
sse2 最快,其次是 float,normal 最慢。
OpenMP
和 MPI 一样,有三种版本,把 --with-mpi 改成
--with-openmp 即可。执行方式为
1 | src/mandelbrot -o time --xr ? --yr 10000 -t ? |
其中 -t 参数为执行绪数,执行期会调用
omp_set_num_threads 修改执行绪数。
采用动态调度方式,因为不同行的计算量不同,静态调度会导致先执行完的执行绪等待后执行完的,不能充分利用计算能力。
程式运行在集群中的一台机器上。
--without-output CXXFLAGS=-O3 --with-openmp --with-sse2
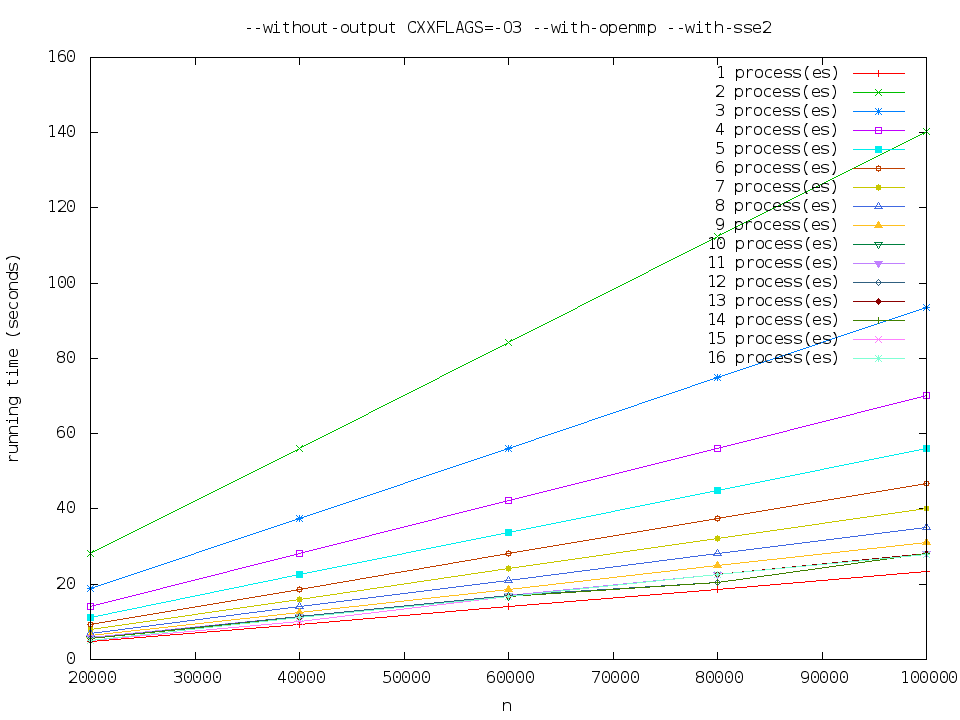
Pthreads
和 OpenMP 一样,有三种版本,把 --with-mpi 改成
--with-pthread 即可。执行方式和 OpenMP 版本相同。 用
1 | ./configure --without-output CXXFLAGS=-O3 --with-pthread |
构建程式。程式运行在集群中的一台机器上。
--without-output CXXFLAGS=-O3 --with-pthread
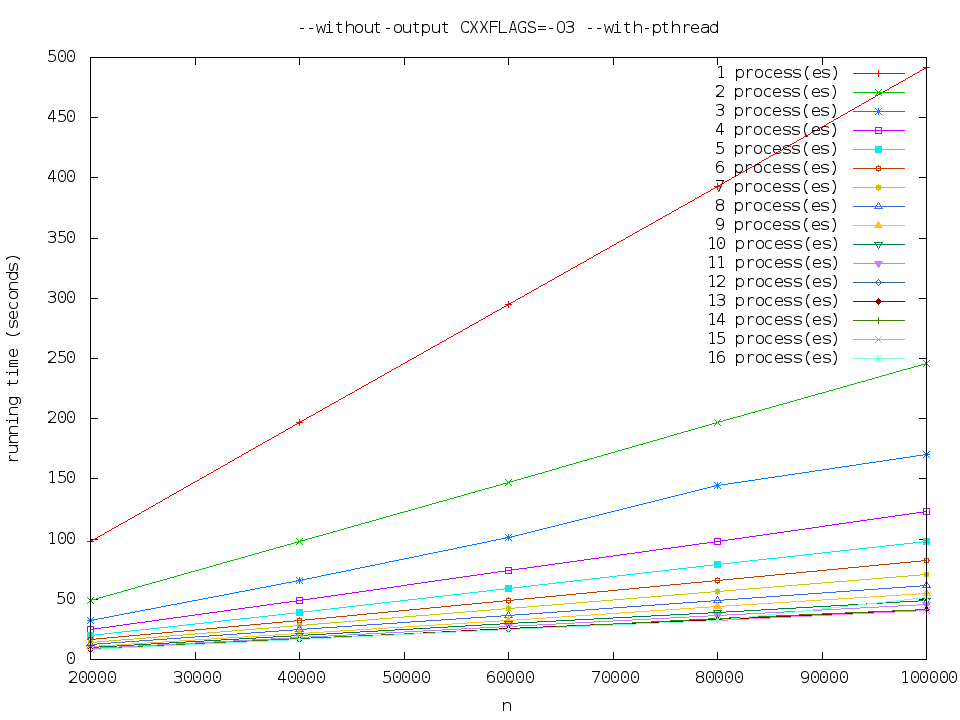
--without-output CXXFLAGS=-O3 --with-pthread --with-float
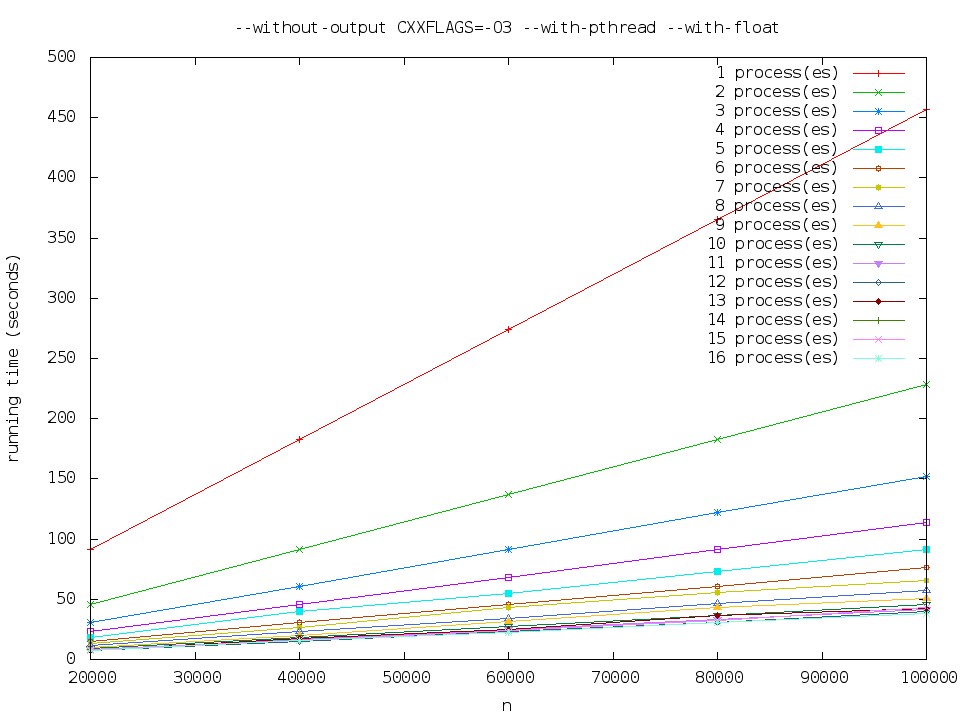
执行时间比 pthread-normal 略少。
--without-output CXXFLAGS=-O3 --with-pthread --with-sse2
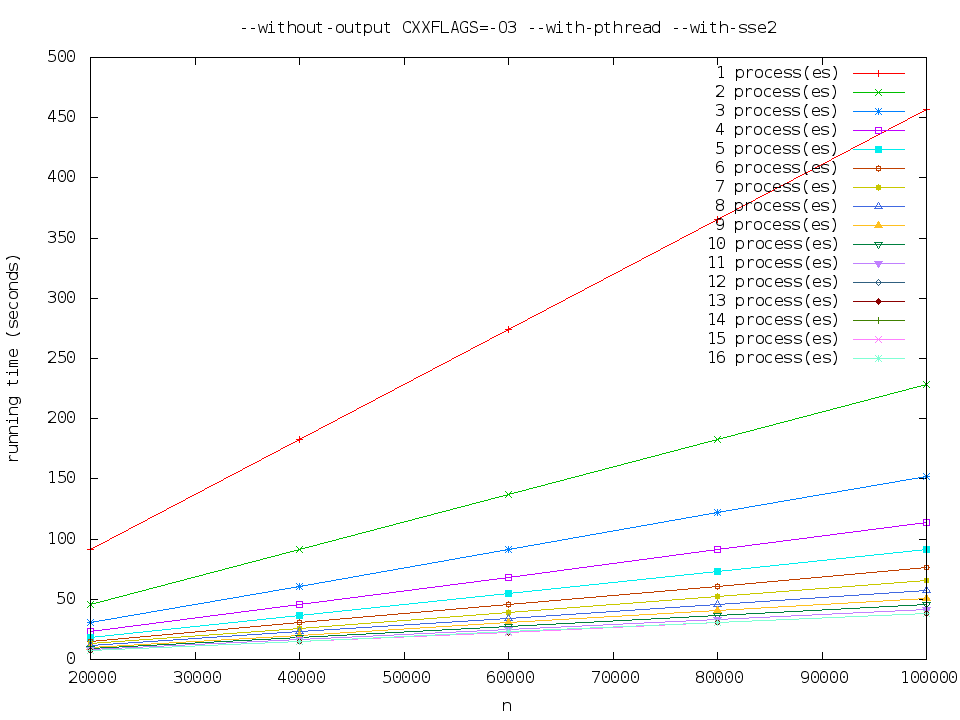
执行时间大致是 pthread-normal 的一半。
三种库的性能比较
在程序/执行续数在
为了考察并行程式提速效果,我还分别对它们相对於单工作程序/执行续的效率进行了测试,
使用了公式
上图中是对 mpi-sse2 的测试,2程序数对应了单工作程序情形,效率为100%,更多程序数时计算的是相对於单工作程序而言的。
可以看出
心得体会
这次作业需要用三种并行库,是对并行程序设计的一次绝佳实践机会。我不希望写成三个不同程序,把计算模块复制三份,所以就考虑用预处理指令。 这样很快就碰到代码难以管理的地步,就仔细设计了这么一个工作模型,让 MPI、Pthreads、OpenMP 三者可以同时开启。 OpenMP 和 Pthreads 工作在执行续层面,用 ThreadSchedule 管理。MPI 在程序层面,由 ProcessSchedule 处理。两者都是动态分配任务的, 使用了 thread pool 模式,但差异还是比较大的,代码不能实现有效的重复利用。
OpenMP 在项目中有效的行数只有1,就是 Core.cc:mandelbrot 中的一个循环前的预处理器指令,但是效果惊人。Pthreads 则需要手写 Channel,考虑任务的调度等, 代码量很大,但得到的效能和 OpenMP 差不多,OpenMP 以如此少的额外代码做到如此高效很让人吃惊。MPI 的代码量就更大了,资料在程序间的递送很麻烦,但可以方便地跨机器使用,还是有很大的价值。
程式开发过程中感受到并行程式调试的麻烦,OpenMP虽然指令不透明,但因为操作简单,只需注意串行实现的变量共用等问题即可。而
Pthreads 程式就要用 gdb 的 thread 功能,MPI
我没找到非常有效的调试方法。目前是采用的方式是让个程序输出 PID
后while(i==0)sleep(1) 停下,用 gdb -p $PID
跟踪进去。
C++ 使用多型的方式过于麻烦。subtype polymorphism必须保证类型是指针或引用, 开发过程中就着了这个道。在此基础上实现 ad-hoc polymorphism(比如程式中的 MutexCallable 的特化)的样本代码也比较长。使用函数对象或函数作为参数也比较麻烦。
程式原始码
在 src/ 目录中。