上周四、五给BCTF 2016出了两道题。
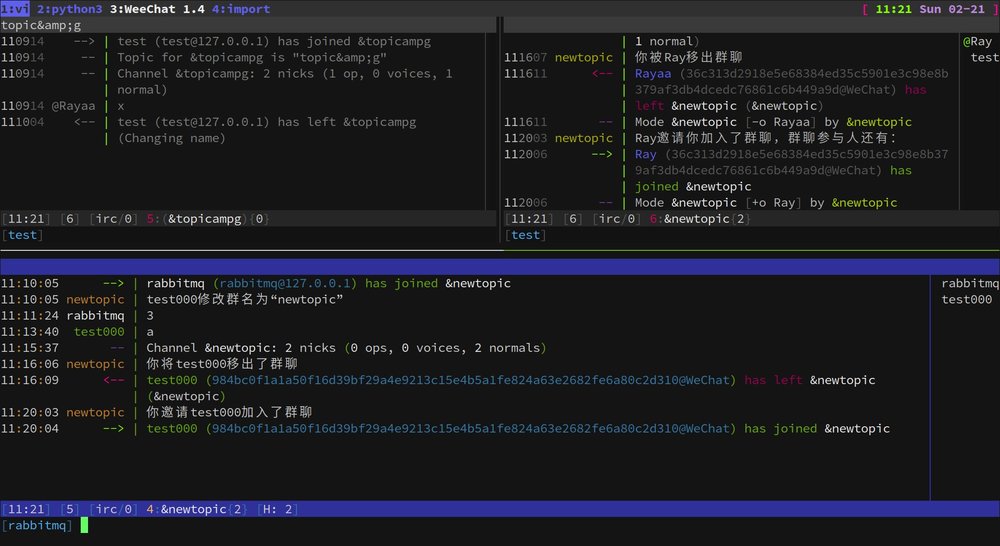
wechatircd——用IRC客户端控制微信网页版
内容可能过时,最新文档参见:https://github.com/MaskRay/wechatircd。
wechatircd
wechatircd在wx.qq.com里注入JavaScript,用WebSocket与IRC
server(wechatircd.py)通信,使得IRC客户端可以收发微信朋友、群消息、设置群名、邀请删除成员等。
1 | IRC WebSocket HTTPS |
安装
需要Python 3.5或以上,支持async/await语法
pip install -r requirements.txt安装依赖
Arch Linux
yaourt -S wechatircd-git。会在/etc/wechatircd/下生成自签名证书。- 把
/etc/wechatircd/cert.pem导入到浏览器(见下文) systemctl start wechatircd会运行/usr/bin/wechatircd --http-cert /etc/wechatircd/cert.pem --http-key /etc/wechatircd/key.pem --http-root /usr/share/wechatircd
IRC服务器默认监听127.0.0.1:6667 (IRC)和127.0.0.1:9000 (HTTPS + WebSocket over TLS)。
如果你在非本机运行,建议配置IRC over TLS,设置IRC connection
password:/usr/bin/wechatircd --http-cert /etc/wechatircd/cert.pem --http-key /etc/wechatircd/key.pem --http-root /usr/share/wechatircd --irc-cert /path/to/irc.key --irc-key /path/to/irc.cert --irc-password yourpassword
可以把HTTPS私钥证书用作IRC over
TLS私钥证书。使用WeeChat的话,如果觉得让WeeChat信任证书比较麻烦(gnutls会检查hostname),可以用:
1
2
3set irc.server.wechat.ssl on`
set irc.server.wechat.ssl_verify off
set irc.server.wechat.password yourpassword`
其他发行版
openssl req -newkey rsa:2048 -nodes -keyout key.pem -x509 -out cert.pem -subj '/CN=127.0.0.1' -days 9999创建密钥与证书。- 把
cert.pem导入浏览器,见下文 ./wechatircd.py --http-cert cert.pem --http-key key.pem
导入自签名证书到浏览器
Chrome/Chromium
- 访问
chrome://settings/certificates,导入cert.pem,在Authorities标签页选择该证书,Edit->Trust this certificate for identifying websites. - 安装Tampermonkey扩展,点击https://github.com/MaskRay/wechatircd/raw/master/injector.user.js安装userscript,效果是在https://wx.qq.com页面注入https://127.0.0.1:9000/injector.js
Firefox
- 访问https://127.0.0.1:9000/injector.js,报告Your connection is not secure,Advanced->Add Exception->Confirm Security Exception
- 安装Greasemonkey扩展,安装userscript

HTTPS、WebSocket over
TLS默认用9000端口,使用其他端口需要修改userscript,启动wechatircd.py时用--web-port 10000指定其他端口。
使用
- 运行
wechatircd.py - 访问https://wx.qq.com,userscript注入的JavaScript会向服务器发起WebSocket连接
- IRC客户端连接127.1:6667(weechat的话使用
/server add wechat 127.1/6667),会自动加入+wechatchannel
在+wechat发信并不会群发,只是为了方便查看有哪些朋友。
微信朋友的nick优先选取备注名(RemarkName),其次为DisplayName(原始JS根据暱称等自动填写的一个名字)
在+wechat channel可以执行一些命令:
help,帮助status [pattern],已获取的微信朋友、群列表,支持 pattern 参数用来筛选满足 pattern 的结果,目前仅支持子串查询。如要查询所有群,由于群由&开头,所以可以执行status &。eval $password $expr: 如果运行时带上了--password $password选项,这里可以eval,方便调试,比如eval $password client.wechat_users
服务器选项
- Join mode,短选项
-j--join auto,默认:收到某个群第一条消息后自动加入,如果执行过/part命令了,则之后收到消息不会重新加入--join all:加入所有channel--join manual:不自动加入--join new:类似于auto,但执行/part命令后,之后收到消息仍自动加入
- 指定不自动加入的群名,用于补充join mode
--ignore 'fo[o]' bar,channel名部分匹配正则表达式fo[o]或bar--ignore-topic 'fo[o]' bar, 群标题部分匹配正则表达式fo[o]或bar
- HTTP/WebSocket相关选项
--http-cert cert.pem,HTTPS/WebSocketTLS的证书。你可以把证书和私钥合并为一个文件,省略--http-key选项。如果--http-cert和--http-key均未指定,使用不加密的HTTP--http-key key.pem,HTTPS/WebSocket的私钥--http-listen 127.1 ::1,HTTPS/WebSocket监听地址设置为127.1和::1,overriding--listen--http-port 9000,HTTPS/WebSocket监听端口设置为9000--http-root ., 存放injector.js的根目录
-l 127.0.0.1,IRC/HTTP/WebSocket监听地址设置为127.0.0.1- IRC相关选项
--irc-cert cert.pem,IRC over TLS的证书。你可以把证书和私钥合并为一个文件,省略--irc-key选项。如果--irc-cert和--irc-key均未指定,使用不加密的IRC--irc-key key.pem,IRC over TLS的私钥--irc-listen 127.1 ::1,IRC over TLS监听地址设置为127.1和::1,overriding--listen--irc-nicks ray ray1,给客户端保留的nick。SpecialUser不会占用这些名字--irc-password pass,IRC connection password设置为pass--irc-port 6667,IRC监听端口
- 服务端日志
--logger-ignore '&test0' '&test1',不记录部分匹配指定正则表达式的朋友/群日志--logger-mask '/tmp/wechat/$channel/%Y-%m-%d.log',日志文件名格式--logger-time-format %H:%M,日志单条消息的时间格式
IRC命令
- 标准IRC channel名以
#开头 - WeChat群名以
&开头。SpecialChannel#update - 联系人带有mode
+v(voice, 通常显示为前缀+)。SpecialChannel#update_detail - 多行消息:
!m line0\nline1 - 多行消息:
!html line0<br>line1 nick0: nick1: test会被转换成@GroupAlias0 @GroupAlias1 test,GroupAlias0是nick0在频道里的Group Alias,如果没设置的话就是Alias。GroupAlias0是移动端用户看到的名字- 回复12:34:SS的消息:
@1234 !m multi\nline\nreply,会发送「Re GroupAlias: text」text - 回复12:34:56的消息:
!m @123456 multi\nline\nreply - 回复朋友/群的倒数第二条消息:
@2 reply
若客户端启用IRC 3.1
3.2的server-time扩展,wechatircd.py会在发送的消息中包含
网页版获取的时间戳。客户端显示消息时时间就会和服务器收到的消息的时刻一致。参见http://ircv3.net/irc/。参见http://ircv3.net/software/clients.html查看IRCv3的客户端支持情况。
WeeChat配置方式: 1
/set irc.server_default.capabilities "account-notify,away-notify,cap-notify,multi-prefix,server-time,znc.in/server-time-iso,znc.in/self-message"
支持的IRC命令:
/cap,列出支持的capabilities/dcc send $nick/$channel $filename, send image or file。This feature borrows the command/dcc sendwhich is well supported in IRC clients. See https://en.wikipedia.org/wiki/Direct_Client-to-Client#DCC_SEND./invite $nick [$channel], invite a contact to the group./kick $nick,删除群成员,群主才有效。由于网页版限制,可能收不到群成员变更的消息/list,列出所有群/mode +m,--join new模式下防止自动重新join。用/mode -m撤销/names, 更新当前群成员列表/part $channel的IRC原义为离开channel,这里表示当前IRC会话中不再接收该群的消息。不用担心,telegramircd并没有主动退出群的功能/query $nick,打开和$nick聊天的窗口/summon $nick $message,发送添加朋友请求,$message为备注消息/topic topic修改群标题。因为IRC不支持channel改名,实现为离开原channel并加入新channel/who $channel,查看群的成员列表
显示
MSGTYPE_TEXT,文本或是视频/语音聊天请求,显示文本MSGTYPE_IMG,图片,显示[Image]跟URLMSGTYPE_VOICE,语音,显示[Image]跟URLMSGTYPE_VIDEO,视频,显示[Video]跟URLMSGTYPE_MICROVIDEO,微视频?,显示[MicroVideo]跟URLMSGTYPE_APP,订阅号新文章、各种应用分享送红包、URL分享等属于此类,还有子分类APPMSGTYPE_*,显示[App]跟title跟URL
QQ表情会显示成<img class="qqemoji qqemoji0" text="[Smile]_web" src="/zh_CN/htmledition/v2/images/spacer.gif">样,发送时用[Smile]即可(相当于在网页版文本输入框插入文本后点击发送)。
Emoji在网页上呈现时为<img class="emoji emoji1f604" text="_web" src="/zh_CN/htmledition/v2/images/spacer.gif">,传送至IRC时转换成单个emoji字符。若使用终端IRC客户端,会因为emoji字符宽度为1导致重叠,参见终端模拟器下使用双倍宽度多色Emoji字体。
JS改动
修改的地方都有//@标注,结合diff,方便微信网页版JS更新后重新应用这些修改。增加的代码中大多数地方都用try catch保护,出错则consoleerr(ex.stack)。原始JS把console对象抹掉了……consoleerr是我保存的一个副本。
目前的改动如下:
webwxapp.js开头
创建到服务端的WebSocket连接,若onerror则自动重连。监听onmessage,收到的消息为服务端发来的控制命令:send_text_message、add_member等。
Hook contactFactory#addContact以记录联系人列表的变更
Python服务端代码
当前只有一个文件wechatircd.py,从miniircd抄了很多代码,后来自己又搬了好多RFC上的用不到的东西……
1 | . |
FAQ
使用这个方法的理由
原本想研究微信网页版登录、收发消息的协议,自行实现客户端。参考过https://github.com/0x5e/wechat-deleted-friends,仿制了https://gist.github.com/MaskRay/3b5b3fcbccfcba3b8f29,可以登录。但根据minify后JS把相关部分重写非常困难,错误处理很麻烦,所以就让网页版JS自己来传递信息。
用途
可以使用强大的IRC客户端,方便记录日志(微信日志导出太麻烦https://maskray.me/blog/2014-10-14-wechat-export),可以写bot。
微信数据获取及控制
少量特殊账户的UserName不带@前缀:newsapp,fmessage,filehelper,weibo,qqmail,fmessage等的;一般账户(公众号、服务号、直接联系人、群友)的UserName以@开头;微信群的UserName以@@开头。不同session
UserName会变化。Uin应该是唯一id,但微信网页版API多数时候都返回0,隐藏了真实值。
群的OwnerUin字段是群主的Uin,但大群用户的Uin通常都为0,因此难以对应。
自己的帐号 1
angular.element(document.body).scope().account
所有联系人列表 1
angular.element($('#navContact')[0]).scope().allContacts
删除群中成员 1
2
3
4
5var injector = angular.element(document).injector()
# 这里获取了chatroomFactory,还可用于获取其他factory、service、controller等
var chatroomFactory = injector.get('chatroomFactory')
# 设置其中的`room`与`userToRemove`
chatroomFactory.delMember(room.UserName, userToRemove.UserName)`
名称中包含xxx的最近联系人列表中的群 1
angular.element($('span:contains("xxx")')).scope().chatContact
当前窗口发送消息 1
2angular.element('pre:last').scope().editAreaCtn = "Hello,微信";
angular.element('pre:last').scope().sendTextMessage();
已知问题
1 | Uncaught TypeError: angular.extend is not a function |
1 | Uncaught TypeError: angular.forEach is not a function |
injector.js得在vendor_*.js后index_*.js前执行。但TamperMonkey无法精细控制script的运行时机。
参考
Gmail的OfflineIMAP XOAUTH2认证
Gmail现在似乎不再允许IMAP的AUTHENTICATE PLAIN了。2016年1月的OfflineIMAP 6.7.0-rc1对XOAUTH2支持较好,仍可访问Gmail IMAP。
支持Android、iOS 9内置IPSec客户端的strongSwan 5.3.5配置
服务器
Arch
Linux可以安装aur/strongswan,Debian可以安装unstable仓库的strongswan和libcharon-extra-plugins。Ubuntu等发行版,软件仓库中strongswan较旧,建议编译安装最新版本。
从ASC'14到ISC'15——我的超算竞赛生涯谢幕
世界上大型超算竞赛有:HPCAC-ISC、SC、ASC,叫做Student Cluster Competition(下面简称为SCC)。今年我也继何斌和fqj1994之后,一共参加过四次大赛了(ASC'14、ISC'14、ASC'15、ISC'15)。比赛期间费尽心力,ASC'14酸楚太多,ISC'14也有憋屈,没有分享其中曲折。ASC'15、ISC'15,清华大学队时隔三年重新捧杯,超算生涯圆满落幕,在此记录些琐事。
Nginx根据Accept-Language的简繁体支持
这个功能开启很久了,但直到昨天才发现遗漏了atom.xml……
我想根据HTTP首部的Accept-Language决定提供简体或繁体的文件。在Chrome中,chrome://settings/languages可以设定偏好语言,浏览器会据此设置Accept-Language首部。较好的处理方式是解析该字段,获取qvalue,根据优先级选取最恰当的语言。但仅用于支持简繁体,我想用取巧的办法:忽略优先级,只要Accept-Language里出现了zh-Hant、zh-TW、zh-HK等字样,就返回繁体,否则返回简体。
指定dynamic linker以使用高版本GCC
今天有人问怎么在没有root的不可更新老旧Linux环境里使用高版本GCC,主要困难在于GCC对glibc版本有一定要求。假设使用现成的GCC二进制包,解压到本地后执行gcc,报错:/lib64/libc.so.6: version `GLIBC_2.14' not found,即系统glibc的libc.so.6中缺乏更高版本的符号(参考info '(ld) VERSION')。使用新符号通常表示API有更新,不过很多时候旧版本的库也能用,可能有两个原因:一是编译机器的库版本可能较新,soname版本号较高,编译出来的可执行文件也会有较高的版本要求;二是源文件因保守指定了较高的版本号,实际上旧版本也能用。
比如最近ncurses主版本号更新到6,/usr/lib/libncursesw.so.5变成了/usr/lib/libncursesw.so.6,导致很多可执行文件没法用了:
皈依Emacs
这应该算第三次使用Emacs了。第一次是在2009年,NOI 2009酱油后下决心好好学习Linux,Philip Xu前辈我指引了两天,发现Linux这个未知世界竟然有这么多好玩的软件。编辑器之神Vim用了一阵子了,NOIP 2009前若干天开始探索神的编辑器Emacs,使用Emacs Lisp配置,实现与Vim相似的设定效果需要多出好多代码,因此不久又回到Vim。大概2010下半年又用起Emacs,这次好好折腾了一把。当时Vim的插件生态还围绕vim.org(现在逐步转战GitHub了),Emacs倒是有个http://www.emacswiki.org,尝试了Mew、ERC、AUCTeX、haskell-mode、org-mode等好多东西。很多文件类型的解析、自动缩进支持比Vim对应物好不少,插件质量感觉也稍高。